Note
1 Python
1.1 简介
主要参考 Python 基础教程 与 Python 3 教程。由于部分特性不常用或者没接触过(数据库相关或网络编程相关),我们将不会深入讨论部分章节。相关代码可以在 Github 上下载。
1.1.1 特点
- 动态类型语言
- 运行期间才做数据类型检查的语言,即动态类型语言编程时,永远不用给任何变量指定数据类型。
- 強类型语言
- 不容忍隐式类型转换。一旦变量被指定某个数据类型,如果不经强制转换,即永远是此数据类型。
- 脚本语言
- 逐行翻译并执行代码。由于缺少了编译过程,即使后面代码中存在语法错误也不影响前面代码的执行。
- 面向对象语言
- 封装:封装成若干个独立单元,只提供接口。能够减少耦合度,提高代码安全性,方便后续修改。
继承:类可以通过另一个类派生而来,新类被称作派生类,原来的类被称作基类,派生类继承了基类的成员方法和变量,并且可以在类里增加自己的特性函数变量实现特定功能。能够提高代码的重用率。
多态:允许不同类对象对同一消息做出反应,同一消息被不同的对象响应可以造成不同的结果。假设类 A 为类 B 的派生类,那么 A 的一个实例 a 将同时拥有 A 与 B 两种状态。进一步假设 B 有类函数 f,那么 A 的实例与 B 的实例都可以直接调用 f,且 A 可以通过重载 f 实现与 B 不一样的功能。
- 封装:封装成若干个独立单元,只提供接口。能够减少耦合度,提高代码安全性,方便后续修改。
- 解释型语言
- 不需要编译成二进制代码,可以直接从源代码运行程序。
1.1.2 优点
- 易于学习、阅读与维护。
- 有广泛的基础库与大量强大的三方库,能够提高开发效率。
- 属于高级语言,不需要我们考虑底层细节。
- 具有可移植性,使程序能够轻易移植到不同的系统平台上。
- 具有可扩展性,允许我们在 python 程序中使用 C/C++ 编写的代码(使用 C/C++ 能提升运行速度并支持代码加密)。
- 具有可嵌入性,允许我们将 python 嵌入到 C/C++ 程序中。
- 可通过 shell 互动执行代码。
- 提供所有主要的商业数据库的接口。
1.1.3 缺点
- 运行速度慢。
- 代码无法加密。
- 多线程无法利用多核 CPU。
1.2 环境
1.2.1 解析器
在脚本第一行添加以下代码能够指定脚本的解析器。
#!/usr/bin/python3
使用以下代码则允许通过环境设置寻找解析器路径。
#!/usr/bin/env python3
1.2.2 编码
可在脚本头添加以下代码指定编码格式。
# -*- coding: utf-8 -*-
utf-8 能支持中文的读取。且外,使用 pickle 读取文件时,有时需要用到 iso-8859-1(欧洲语言)。
1.3 基础
1.3.1 标识符
在 python 中,所有标识符可以包括英文(区分大小写)、数字以及下划线,但不能以数字开头。
foo # 合法
FOO # 合法
foo123 # 合法
f_oo # 合法
foo_ # 合法
123foo # 非法
其中,以下划线开头的标识符是有特殊意义的。
# class definition
class A:
# 代表不能直接访问的类属性,需通过类提供的接口进行访问。
# 不能用 from xxx import * 而导入。
def _foo(self):
pass
# 代表类的私有成员。
def __foo(self):
pass
# 代表 Python 里特殊方法专用的标识,如 __init__() 代表类的构造函数。
def __foo__(self):
pass
# main function
a = A()
a._foo() # 可以调用,但是会有 warning
a.__foo() # 无法调用,会报错
a._A__foo() # 强行在外部调用 a._foo()
在 python 中,使用分号能令同一行显示多条语句。
print("hello"); print("world");
1.3.2 保留字
| and(逻辑与) | exec(执行储存在字符串或文件中的Python语句) | not(逻辑非) |
| assert(断言) | finally(异常捕捉) | or(逻辑或) |
| break(终止循环) | for(循环) | pass(空语句) |
| class(类定义) | from(指定域) | print(打印) |
| continue(跳过循环) | global(全局变量修饰词) | raise(引发异常) |
| def(函数定义) | if(条件) | return(返回) |
| del(解除引用) | import(导入) | try(异常捕捉) |
| elif(等同于 else if) | in(成员运算符) | while(循环) |
| else(条件) | is(对象比较) | with(上下文管理,try … finally 的简写) |
| except(异常捕捉) | lambda(lambda 表达式) | yield(生成器) |
| as(赋值) | None(空值) |
1.3.3 格式
python 的代码块不使用 {},而是使用缩进,来控制类、函数以及其他逻辑判断。缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量。
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
# 没有严格缩进,在执行时会报错
print ("False")
在 python 中,我们可以使用( \ )将一行的语句分为多行显示。若语句中包含 [], {} 或 () 则不需要使用多行连接符。
sum = 1 + \
2 + \
3
days = ['Monday', 'Tuesday', 'Wednesday',
'Thursday', 'Friday']
python 可以使用引号( ‘ )、双引号( “ )、三引号( ‘’’ 或 “”” ) 来表示字符串,引号的开始与结束必须的相同类型的。
word = 'word'
sentence = "这是一个句子。"
paragraph = """这是一个段落。
包含了多个语句"""
python中单行注释采用 # 开头;多行注释使用三个单引号或三个双引号。
# 单行注释
'''
多行注释
多行注释
'''
"""
多行注释
多行注释
"""
1.3.4 输入与输出
input() 函数,能接收任意输入,将所有输入默认为字符串处理,并返回字符串类型。
a = input("please input an integer: ")
print(a, type(a))
b = input("please input a float number: ")
print(b, type(b))
c = input("please input a string: ")
print(c, type(c))
1.4 变量类型
python 的标准数据类型有:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
使用下面代码进行赋值,能够让代码更简洁:
a = b = c = 1
a, b, c = 2020, 3.14, 'python'
1.4.1 Numbers
Numbers 包括以下类型:
- int(整型)
- float(浮点型)
- complex(复数)
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3e+18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2E-12 | 4.53e-7j |
在 python 中,二进制数以 0b 开头(如 0b10 == 2);八进制数以 0o 开头(如 0o10 == 8);十六进制数以 0x 开头(如 0x10 == 16)。且外,复数(常见于滤波算法)由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型。一般情况下,我们可能不需要用到二进制数、八进制数、十六进制数与复数。在处理大数字时,使用科学计数法能让代码更简洁(如 1e3 == 1000)。
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。详情可参考 NumPy 数据类型。且外,np.inf(正无穷) 与 np.nan(无效值) 也非常实用。
1.4.2 String
python 不支持单字符类型,单字符在 python 中也是作为一个字符串使用。
var1 = 'python'
var2 = 'p'
python 访问子字符串,可以使用方括号来截取字符串。
print(var1[1:4])
print(var2[0])
在需要在字符中使用特殊字符时,我们要使用以下转义字符:
- \,续行符
- \\,反斜杠
- \‘,单引号
- \“,双引号
- \n,换行符
- \t,制表符
- \a,在 shell 中输入时 print(“\a”) 时,系统会发出响铃声
- \b,退格符,执行 print(“xy\bz”) 会得到 xz
- \r,回车符
- \v,纵向制表符
- \f,换页符
- \000,空
在 python 中,字符串支持以下运算符:
- +
- *
- []
- [:]
- in
- not in
- r
- R
- %
python 支持格式化字符串的输出。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。在 python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
python 字符串格式化符号:
- %c,格式化字符及其ASCII码
- %s,格式化字符串
- %d,格式化整数
- %u,格式化无符号整型
- %o,格式化无符号八进制数
- %x,格式化无符号十六进制数
- %X,格式化无符号十六进制数(大写)
- %f,格式化浮点数字,可指定小数点后的精度
- %e,用科学计数法格式化浮点数
- %E,作用同%e,用科学计数法格式化浮点数
- %g,%f和%e的简写
- %G,%f 和 %E 的简写
- %p,用十六进制数格式化变量的地址(在 python3 中不适用)
格式化操作符辅助指令:
- *,定义宽度或者小数点精度
- -,用做左对齐
- +,在正数前面显示加号( + )
-
,在正数前面显示空格 - #,在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’)
- 0,显示的数字前面填充’0’而不是默认的空格
- %,’%%’输出一个单一的’%’
- (var),映射变量(字典参数)
- m.n.,m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话)
f-string 的细节与更多的字符串内建函数可参考 Python3 字符串。
1.4.3 List
列表是最常用的 python 数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型。
访问列表中的值:
list1 = ['Google', 'Now', 1997, 2020]
list2 = list(range(1, 7))
print("list1[0]: ", list1[0])
print("list2[1:5]: ", list2[1:5])
更新列表:
list1 = ['Google', 'Now', 1997, 2020]
print("第三个元素为 : ", list1[2])
list1[2] = 2001
print("更新后的第三个元素为 : ", list1[2])
删除列表元素:
list1 = ['Google', 'Now', 1997, 2020]
print("原始列表 : ", list1)
del list1[2]
# 或 list1.pop(2)
print("删除第三个元素 : ", list1)
更多细节可参考 Python3 列表。
1.4.4 Tuple
python 的元组与列表类似,不同之处在于元组的元素不能修改。
tup1 = ('Google', 'Now', 1997, 2020)
tup2 = (1, 2, 3, 4, 5)
tup3 = "a", "b", "c", "d" # 不需要括号也可以
print(tup1, tup2, tup3)
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用。
tup4 = (50)
print(tup4) # 不加逗号,类型为整型
tup4 = (50,)
print(tup4) # 加上逗号,类型为元组
访问元组:
tup1 = ('Google', 'Now', 1997, 2020)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0])
print("tup2[1:5]: ", tup2[1:5])
修改元组:元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = ('Google', 'Now', 1997, 2020)
tup2 = (1, 2, 3, 4, 5, 6, 7)
tup3 = tup1 + tup2
print(tup3)
删除元组:元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
tup1 = ('Google', 'Now', 1997, 2020)
tup2 = (1, 2, 3, 4, 5, 6, 7)
tup3 = tup1 + tup2
del tup3
print(tup3)
更多细节可参考 Python3 元组。
1.4.5 Dictionary
字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值 (key => value) 对用冒号分割,每个对之间用逗号分割,整个字典包括在花括号中。
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict2 = { 'abc': 456 }
dict3 = { 'abc': 123, 98.6: 37 }
访问字典里的值:
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
print("dict['Alice']: ", dict1['Alice'])
print("dict['Cecil']: ", dict1['Cecil'])
修改字典:
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
dict1['Alice'] = '1432'
dict1['Eddie'] = '1996'
print(dict1)
删除字典元素:
dict1 = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
del dict1['Eddie']
# dict1.clear() 清空字典
print(dict1)
字典的特性:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行。
- 字典查找速度快,无论有10个元素还是10万个元素,查找速度都一样。而列表的查找速度随着元素增加而逐渐下降。不过查找速度快不是没有代价的,缺点是占用内存大,还会浪费很多内容,列表正好相反,占用内存小,但是查找速度慢。
- 字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的。
- 字典存储的key-value序对是没有顺序的。
综上,假设我们需要频繁使用查找操作,使用 dict 会更加合理。
list1 = list(range(int(1e6)))
dict1 = dict(zip(list1, list1))
print(54502 in list1)
print(54502 in dict1)
更多细节可参考 Python3 字典。
且外,某些情况下,集合可以是字典的一个替代。
1.5 运算符
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
更多细节可参考 Python 运算符。
其中,**(幂运算)与 //(整除运算)是比较实用却容易被忽略的算术运算符。
1.6 条件语句
python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
if expression:
operation
elif expression:
operation
else:
operation
由于 python 并不支持 switch 语句,所以多个条件判断,只能用 elif 来实现。且外,你也可以在同一行的位置上使用 if 条件判断语句(在我看来,不是一个好习惯)。
var = 100
if var == 100: print("变量 var 的值为100")
如果接触过 C++ 的话,那可能会听说过条件运算符(a ? b : c)。在 python 中,我们也可以使用类似的语法糖(某些情况下,能够让代码更简洁)。
def isOdd(num):
return ("%d 是一个奇数" if num % 2 == 1 else "%d 不是一个奇数") % num
print(isOdd(241))
print(isOdd(8832))
>> 241 是一个奇数
>> 8832 不是一个奇数
1.7 循环语句
循环语句允许我们执行一个语句或语句组多次。python 提供了 for 循环和 while 循环。
for 循环:
for var in sequence:
statements
while 循环:
while condition:
statements
循环控制语句可以更改语句执行的顺序。python支持以下循环控制语句:
- break
- continue
- pass
1.8 日期与时间
可参考 Python 日期和时间。
在这里,我们简略地介绍下几种常用的应用。
计算某段代码的执行时间:
import time
tick = time.time()
for i in range(int(1e8)):
pass
print("executed in %f seconds" % (time.time() - tick))
将时间戳转换为日期(一种特征工程):
import time
print(time.localtime(20647191))
>> time.struct_time(tm_year=1970, tm_mon=8, tm_mday=28, tm_hour=7, tm_min=19, tm_sec=51, tm_wday=4, tm_yday=240, tm_isdst=0)
格式化日期:
import time
print(time.strftime("%Y-%m-%d %H:%M:%S %a", time.localtime()))
python 中时间日期格式化符号:
- %y,两位数的年份表示(00-99)
- %Y,四位数的年份表示(000-9999)
- %m,月份(01-12)
- %d,月内中的一天(0-31)
- %H,24小时制小时数(0-23)
- %I,12小时制小时数(01-12)
- %M,分钟数(00=59)
- %S,秒(00-59)
- %a,本地简化星期名称
- %A,本地完整星期名称
- %b,本地简化的月份名称
- %B,本地完整的月份名称
- %c,本地相应的日期表示和时间表示
- %j,年内的一天(001-366)
- %p,本地A.M.或P.M.的等价符
- %U,一年中的星期数(00-53)星期天为星期的开始
- %w,星期(0-6),星期天为星期的开始
- %W,一年中的星期数(00-53)星期一为星期的开始
- %x,本地相应的日期表示
- %X,本地相应的时间表示
- %Z,当前时区的名称
- %%,%号本身
将格式字符串转换为时间戳(一种特征工程):
import time
today = "2020-01-04 03:25:50 Sat"
print(time.mktime(time.strptime(today, "%Y-%m-%d %H:%M:%S %a")))
1.9 函数
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
1.9.1 参数传递
在 python 中,类型属于对象,变量是没有类型的:
a = [1,2,3]
a = "Hello"
以上代码中,[1,2,3] 是 List 类型,”Hello” 是 String 类型,而变量 a 是没有类型,仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象。
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a = 5 后再赋值 a = 10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
- 可变类型:变量赋值 la = [1,2,3,4] 后再赋值 la[2] = 5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
- 不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
- 可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的la也会受影响。
实际开发中,特别需要注意不可变类型与可变类型的区别。
1.9.2 参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
调用函数时,如果没有传递参数,则会使用默认参数。
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述参数不同,声明时不会命名。
1.9.3 匿名函数
python 使用 lambda 来创建匿名函数。所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda [arg1 [,arg2,.....argn]]:expression
1.9.4 函数注解
python3 提供一种语法,用于为函数声明中的参数和返回值附加元数据。
- 函数声明中的各个参数可以在:后增加注解表达式。
- 如果参数由默认值,注解放在参数名和 = 号之间。
- 如果注解有返回值,在 ) 和函数末尾的:之间增加 -> 和一个表达式。那个表达式可以是任何类型。注解中最常用的类型是类(如 str 或 int)和字符串(如 ‘int > 0’)。
python 对注解所做的唯一的事情是,把他们存储在函数的 __annotations__ 属性里。python 不会做任何检查、强制、验证。注解对 python 解释器没任何意义。注解只是元数据,可以供 IDE、框架和装饰器等工具使用。(参数类型不正确或返回类型不正确时,IDE 会有高亮提示。)
1.10 迭代器与生成器
1.10.1 迭代器
迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__()。
这部分内容估计很少会用到。一般在定义一些复杂的数据结构(提供一种遍历方法)或者是生成序列(用迭代器获取斐波拉契数列的下一个数)的时候才会用到迭代器。
1.10.2 生成器
在 python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。调用一个生成器函数,返回的是一个迭代器对象。
之前提过的列表生成式也可以看作一种生成器,但它会一次生成完所有的元素。通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。如果列表元素可以按照某种算法推算出来,这样就不必创建完整的 list,从而节省大量的空间。
为了实现与生成器对象的交互,生成器还提供了 send、throw 和 close 方法。
send 方法有一个参数,该参数指定的是上一次被挂起的 yield 语句的返回值。总的来说,send 方法和 next 方法唯一的区别是在执行 send 方法会首先把上一次挂起的 yield 语句的返回值通过参数设定,从而实现与生成器方法的交互。但是需要注意,在一个生成器对象没有执行 next 方法之前,由于没有 yield 语句被挂起,所以执行 send 方法会报错。
throw 方法是通过向生成器对象在上次被挂起处,抛出一个异常。之后会继续执行生成器对象中后面的语句,直至遇到下一个 yield 语句返回。如果在生成器对象方法执行完毕后,依然没有遇到 yield 语句,抛出 StopIteration 异常。
生成器对象的 close 方法会在生成器对象方法的挂起处抛出一个 GeneratorExit 异常。GeneratorExit 异常产生后,系统会继续把生成器对象方法后续的代码执行完毕。
1.11 模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是 .py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
想使用 Python 源文件,只需在另一个源文件里执行 import 语句。当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。使用 pycharm 开发的话,项目的根目录会被添加到搜索路径中。
import sys
import os
python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。
from random import random
把一个模块的所有内容全都导入到当前的命名空间也是可行的。
from random import *
且外,我们也可以在导入模块时,对模块进行重命名,也就是给模块起一个别名。
import numpy as np
from numpy import inf as INFINITY
最后,一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用 __name__ 属性来使该程序块仅在该模块自身运行时执行。(类似于 C++ 的 main 函数)
if __name__ == '__main__':
print("hello world")
假设我们的项目结构如下:
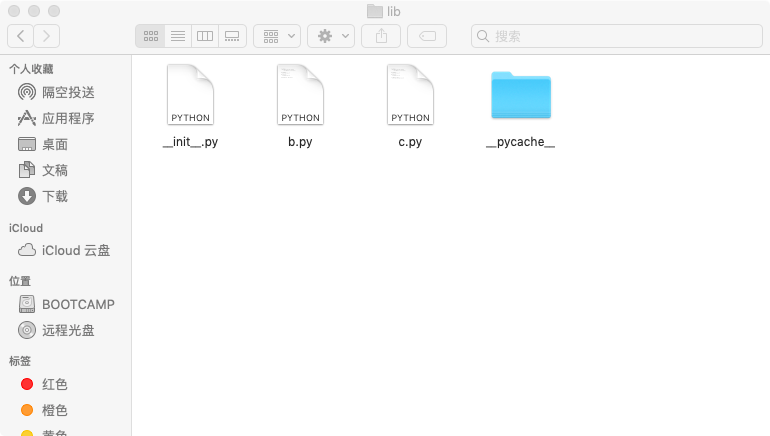
我们对 b.py、c.py 作如下修改:
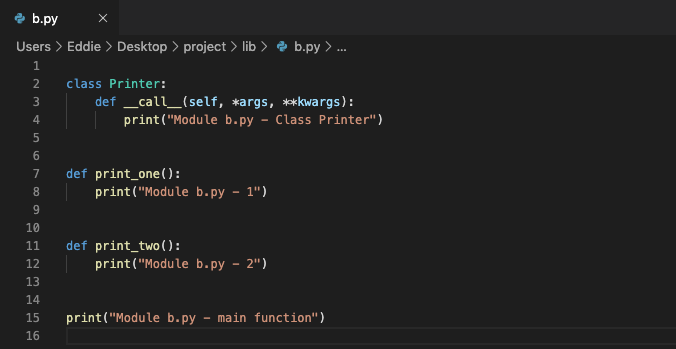
我们可以尝试在 a.py 中导入不同的模块。
# 一个模块被另一个程序第一次引入时,其主程序将运行
from lib import b
if __name__ == '__main__':
pass
>> Module b.py - main function
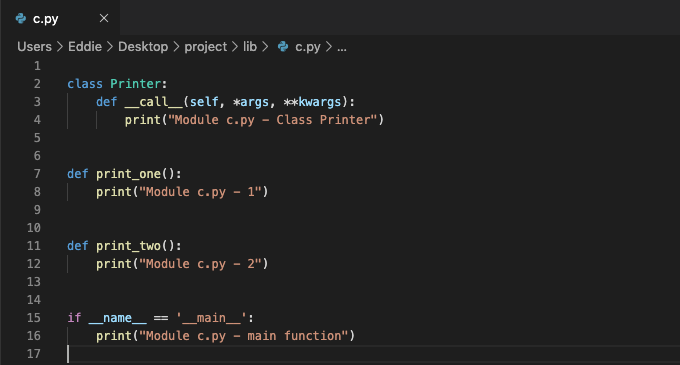
# 使用 __name__ 属性来使 c.py 的主程序仅在该模块自身运行时执行
import lib.c
if __name__ == '__main__':
pass
>>
from lib.b import Printer
if __name__ == '__main__':
p = Printer()
p()
>> Module b.py - main function
>> Module b.py - Class Printer
from lib.b import print_one
if __name__ == '__main__':
print_one()
>> Module b.py - main function
>> Module b.py - 1
from lib.c import *
if __name__ == '__main__':
print_one()
print_two()
>> Module c.py - 1
>> Module c.py - 2
from lib.b import Printer as BPrinter
from lib.c import Printer as CPrinter
if __name__ == '__main__':
BPrinter()()
CPrinter()()
>> Module b.py - main function
>> Module b.py - Class Printer
>> Module c.py - Class Printer
1.12 命名空间和作用域
1.12.1 命名空间
命名空间是从名称到对象的映射,大部分的命名空间都是通过 python 字典来实现的。命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
命名空间查找顺序:局部 -> 全局 -> 内置。
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此,我们无法从外部命名空间访问内部命名空间的对象。
1.12.2 作用域
作用域就是一个 python 程序可以直接访问命名空间的正文区域。在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。
python 的作用域一共有 4 种,分别是:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部 (non-local) 也非全局 (non-global) 的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等。
规则顺序:L –> E –> G –> B
python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else、try/except、for/while 等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问。
当内部作用域想修改外部作用域的变量时,需要用到 global 或 nonlocal关键字。
1.13 输入和输出
1.13.1 str() 与 repr()
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
import datetime
datetime.datetime.now()
>>> datetime.datetime(2018, 9, 30, 18, 50, 35, 860171)
print(datetime.datetime.now())
>>> 2018-09-30 18:50:41.618557
print(repr(datetime.datetime.now()))
>>> datetime.datetime(2018, 9, 30, 18, 56, 11, 277455)
print(str(datetime.datetime.now()))
>>> 2018-09-30 18:50:41.618557
打印操作会首先尝试 __str__ 和 str 内置函数(print 运行的内部等价形式),它通常应该返回一个友好的显示。__repr__ 用于所有其他的环境中:用于交互模式下提示回应以及 repr 函数,如果没有使用 __str__,会使用 print 和 str。它通常应该返回一个编码字符串,可以用来重新创建对象,或者给开发者详细的显示。
- __repr__ 可以在交互环境中直接输出,而 __str__ 必须是 print(),或者 str()。
- __repr__ 返回结果应更准确,用于程序员调试,而 __str__ 返回结果可读性强,用于用户友好显示。
# 重构__repr__
class TestRepr():
def __init__(self, data):
self.data = data
def __repr__(self):
return 'TestRepr(%s)' % self.data
>>> tr = TestRepr('5')
>>> tr
TestRepr(5)
>>> print(tr)
TestRepr(5)
# 重构__str__
class TestStr():
def __init__(self, data):
self.data = data
def __str__(self):
return '[Value: %s]' % self.data
>>> ts = TestStr('5')
>>> ts
<__main__.TestStr at 0x7fa91c314e50>
>>> print(ts)
[Value: 5]
## 重构__str__ 和__repr__
class Test():
def __init__(self, data):
self.data = data
def __repr__(self):
return 'Test(%s)' % self.data
def __str__(self):
return '[Value: %s]' % self.data
t = Test('5')
t
>>> Test(5)
print(t)
>>> [Value: 5]
同时重构 __str__ 和 __repr__ 时,print() 输出时 __str__ 会覆盖 __repr__,即 在交互环境直接输出时自动调用 __repr__,而在 print() 输出时自动调用 __str__。
- 假设我们直接使用 print() 输出时会优先调用 __str__。
- 假设我们将对象存放在一个列表里,然后我们直接输出该列表时,python 会调用 __repr__。
repr() 的返回值一般可以用 eval() 函数来还原对象,通常来说有如下等式。
obj = str()
print(obj == eval(repr(obj)))
1.13.2 输出格式美化
另一个方法 zfill(), 它会在数字的左边填充 0。对齐。字符串对象的 rjust() 方法, 它可以将字符串靠右, 并在左边填充空格。还有类似的方法, 如 ljust() 和 center()。
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# 注意前一行 'end' 的使用
print(repr(x*x*x).rjust(4))
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
str.format() 的基本使用如下:
# 基础用法
print("{} {}".format('Hello', 'World'))
# 指定位置
print("{0} {1}".format('Hello', 'World'))
print("{1} {0}".format('Hello', 'World'))
# 使用关键字
print("{verb} {noun}".format(verb='Hello', noun='World'))
# 位置及关键字参数
print("{0} {noun}".format('Hello', noun='World'))
# !a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化
import datetime
now = datetime.datetime.now()
print("{0!s}, {0!r}".format(now))
# 可选项 : 和格式标识符可以跟着字段名
# 指定小数位数
pi = 3.141592653589793
print("{0:.3f}".format(pi))
# 指定宽度
prices = {'banana': 1, 'apple': 2, 'mango': 3}
for (fruit, price) in prices.items():
print('{0:10} ==> {1:10d}'.format(fruit, price))
如果你有一个很长的格式化字符串, 而你不想将它们分开, 那么在格式化时通过变量名而非位置会是很好的事情:
prices = {'banana': 1, 'apple': 2, 'mango': 3}
print('banana: {0[banana]:d}; apple: {0[apple]:d}; mango: {0[mango]:d}'.format(prices))
print('banana: {banana:d}; apple: {apple:d}; mango: {mango:d}'.format(**prices))
1.13.3 键盘输入
python提供了 input() 内置函数从标准输入读入一行文本,默认的标准输入是键盘。input 可以接收一个 python 表达式作为输入,并将运算结果返回。
content = input("please input a sentence: ")
print(content)
1.14 文件读取
python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
f = open(file, mode='r')
f = open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- r,以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
- rb,以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。
- r+,打开一个文件用于读写。文件指针将会放在文件的开头。
- rb+,以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
- w,打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- wb,以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- w+,打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- wb+,以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- a,打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- ab,以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- a+,打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
- ab+,以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件,而且写起来也比 try - finally 语句块要简短。
with open(file, 'r') as f:
data = f.read()
print(f.closed)
1.14.1 pickle 模块
python 的 pickle 模块实现了基本的数据序列和反序列化。
- 通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储。
- 通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
# 将对象 obj 保存到文件 file 中去。
pickle.dump(obj, file, [,protocol])
# 读取文件 file
data = pickle.load(file)
其中:
- protocol 为序列化使用的协议版本。其中协议 0 和 1 兼容老版本的 python。protocol默认值为0。protocol 的值为 -1 时,代表使用最高的协议。一般来说,我们不指定协议也可以。
- 0:ASCII协议,所序列化的对象使用可打印的ASCII码表示;
- 1:老式的二进制协议;
- 2:2.3版本引入的新二进制协议,较以前的更高效。
- file 为对象保存到的类文件对象。file 必须有 write() 接口, file 可以是一个以 ‘w’ 方式打开的文件或者一个 StringIO 对象或者其他任何实现 write() 接口的对象。如果 protocol>=1,文件对象需要是二进制模式打开的。
对于 pickle 模块,比较常用的使用方法有:保存一个训练好的模型和保存一组参数。
1.15 系统操作
os 模块提供了非常丰富的方法用来处理文件和目录。详细内容可参考 Python3 OS 文件/目录方法 与 Python3 os.path() 模块。
接下来,将结合具体场景来介绍一些常用的 os 函数。
在上一章提到,我们可以使用 pickle 来保存训练好的 scikit-learn 模型。假设我们使用以下代码来保存模型:
1.15.1 创建文件夹
# 保存模型
with open('save/sklearn.pickle', 'wb') as f:
pickle.dump(tree, f)
如果在当前的目录下没有 save 这个文件夹,python 将会显示以下的报错信息:
FileNotFoundError: [Errno 2] No such file or directory: 'save/sklearn.pickle'
此时,我们需要在代码中创建名为 save 的文件夹来避免报错:
# 创建文件夹
os.mkdir('save')
# 保存模型
with open('save/sklearn.pickle', 'wb') as f:
pickle.dump(tree, f)
1.15.2 路径检测
继续先前的假设,假设我们要执行以下代码:
# 创建文件夹
os.mkdir('save')
# 保存模型
with open('save/sklearn.pickle', 'wb') as f:
pickle.dump(tree, f)
如果当前的目录下已经存在 save 这个文件夹,python 将会显示以下的报错信息:
FileExistsError: [Errno 17] File exists: 'save'
为了避免这一情况,我们进一步修改之前的代码:
# 检测 save 文件夹是否存在
if not os.path.isdir('save'):
# 创建文件夹
os.mkdir('save')
# 保存模型
with open('save/sklearn.pickle', 'wb') as f:
pickle.dump(tree, f)
运行修改后的代码,我们就可以在 save 文件夹不存在时自动生成 save 文件夹来避免报错。
除了可以检测文件夹是否存在之外,我们也可以检测文件是否存在来避免覆盖掉已经训练好的模型:
# 检测模型是否存在
if not os.path.exists('save/sklearn.pickle'):
with open('save/sklearn.pickle', 'wb') as f:
pickle.dump(tree, f)
在此基础上,我们还有一种更加严谨的写法:
# 检测文件是否存在
if os.path.exists(self.filenames):
# 要求用户输入指令
flag = input('file %s already exists, do you want to remove it? [y/n]\n' % self.filenames)
if flag == 'y':
# 移除已经存在的文件
os.remove(self.filenames)
elif flag == 'n':
# 抛出文件存在错误
raise FileExistsError
else:
# 抛出输入值错误
raise ValueError
with open(self.filenames, 'wb') as f:
pickle.dump(tree, f)
1.15.3 路径合成
假设我们要训练并保存多个模型,我们需要为不同的模型单独命名。此时,我们可以使用路径合成来命名:
path = 'save/'
with open(os.path.join(path, time.strftime('%Y-%m-%d_%H-%M-%S.pkl', time.localtime(time.time()))), 'wb') as f:
pickle.dump(tree, f)
with open(os.path.join(path, time.strftime('%Y-%m-%d_%H-%M-%S.pkl', time.localtime(time.time()))), 'wb') as f:
pickle.dump(tree, f)
除了上述的合成方式外,下列的合成方式也是可以的:
print(os.path.join('.', time.strftime('%Y-%m-%d_%H-%M-%S.pkl', time.localtime(time.time()))))
>>> ./2020-01-14_13-47-14.pkl
print(os.path.join('.', 'save', time.strftime('%Y-%m-%d_%H-%M-%S.pkl', time.localtime(time.time()))))
>>> ./save/2020-01-14_13-47-40.pkl
# os.getcwd() 可获取当前工作路径
print(os.path.join(os.getcwd(), time.strftime('%Y-%m-%d_%H-%M-%S.pkl', time.localtime(time.time()))))
>>> /Users/Eddie/Desktop/Note/2020-01-14_13-48-32.pkl
1.15.4 文件检索
假如我们的数据集里有很多文件,且文件的种类不止一种,我们可以先获取所有文件的名字再分别对它们进行处理:
# obtain available data automatically
files = os.listdir(self.path)
上述的 files 变量为一个包含所有文件名字的 lists。在此基础上,我们可以使用正则表达式(将在后文中介绍)对这些文件进行分类筛选:
# 获取所有文件名
files = os.listdir(self.path)
# 定义正则规则
regulation = [r'\d+_dataset_info.txt', r'\d+_fit_crop_info.txt'
r'\d+_image.png', r'\d+_render_light.png', r'\d+_joints.npy', r'\d+_body.pkl']
# 按规则分类
category = []
for r in regulation:
p = re.compile(r)
target = []
for name in files:
if re.match(p, name):
target.append(name)
category.append(target)
# judge the validity of data
category[0].sort(key=lambda x: x[0:5])
for i in range(1, len(category)):
if len(category[i]) != len(category[i-1]):
raise ValueError('Incomplete sample or redundant sample exists')
category[i].sort(key=lambda x: x[0:5])
# create tfrecord
for index in range(len(category[0])):
for i in range(1, len(category)):
if category[i][index][0:5] != category[i-1][index][0:5]:
raise ValueError('Mismatched sample exists at index %d' % index)
info_path = self.path + category[0][index]
crop_info_path = self.path + category[1][index]
image_path = self.path + category[2][index]
silhouette_path = self.path + category[3][index]
keypoint_path = self.path + category[4][index]
mesh_path = self.path + category[5][index]
# serialize
self.__serialize(info_path, crop_info_path, image_path, silhouette_path, keypoint_path, mesh_path)
self.writer.close()
1.15.5 文件权限
我们在读写某些文件时,可能会遇到没有权限的情况。此时,我们可以使用下面的函数来修改文件的权限:
os.chmod(path, mode)
具体的使用可以参考 Python3 os.chmod() 方法
1.16 错误和异常
1.16.1 语法错误
python 的语法错误或者称之为解析错。当我们运行有语法错误的代码时,语法分析器会抛出 SyntaxError,并指出了出错的位置。建议使用 PyCharm、Spyder 等 IDE 进行开发,这些 IDE 可以提供 itellisense 的功能。
File "/Users/Eddie/Desktop/Note/tmp.py", line 4
a = b -= c
^
SyntaxError: invalid syntax
1.16.2 异常捕捉
即便 python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
最简单的异常检测方式是使用 assert 语句。python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常(AssertionError)。
assert 的语法格式如下:
assert expression [, arguments]
它等价于(将在后文详细介绍):
if not expression:
# 使用 raise 来抛出错误
raise AssertionError(arguments)
假如我们在遇到异常的时候,希望程序能够处理这些错误,我们需要使用异常捕捉语句。异常捕捉可以使用 try/except 语句。下面是一个例子:
# 简单的 try/except
while True:
try:
dividend = int(input("please input the dividend: "))
divisor = int(input("please input the divisor: "))
break
except ValueError as err:
print("please input again: %s. " % err)
程序会先尝试执行 try 里面的内容。假如没有异常发生,则忽略 except 子句,并在 try 子句执行后结束。如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行;如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。 处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。
一个 except 子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组:
while True:
try:
dividend = int(input("please input the dividend: "))
divisor = int(input("please input the divisor: "))
print("{} / {} = {}".format(dividend, divisor, dividend / divisor))
break
except (ValueError, ZeroDivisionError) as err:
print("please input again: %s. " % err)
最后一个 except 子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。else 子句将在 try 子句没有发生任何异常的时候执行。
while True:
try:
dividend = int(input("please input the dividend: "))
divisor = int(input("please input the divisor: "))
result = dividend / divisor
except (ValueError, ZeroDivisionError) as err:
print("please input again: %s. " % err)
else:
print("{} / {} = {}".format(dividend, divisor, result))
break
try/finally 语句中的 finally(finally 可以理解为清理行为)无论异常是否发生都会执行。
1.16.3 抛出异常
python 使用 raise 语句抛出一个指定的异常。
raise [Exception [, args [, traceback]]]
下面是一个简单的例子:
while True:
try:
negative = int(input("please input a negative integer: "))
# 当输入不为负数时,抛出异常
if negative >= 0:
raise ValueError("non-negative inputs are not expected")
except ValueError as err:
print("please input again: %s" % err)
else:
print("your input is {}".format(negative))
break
假如使用上述的语句抛出异常,我们虽然得到了错误的日志输出,但是不知道为什么出错,也不能定位具体出错位置。我们进一步使用 trackback 即可得到具体的错误,以及定位到出错的位置。我们还可以通过创建一个新的异常类来拥有自己的异常(通常不需要这样做)。至于如何自定义异常,可参考 Python3 错误和异常。
1.17 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。python 的 re 模块使 python 语言拥有全部的正则表达式功能。
首先,’r’ 是防止字符转义的 如果路径中出现 ‘\t’ 的话,不加 ‘r’ 的话 ‘\t’ 就会被转义 而加了 ‘r’ 之后 ‘\t’ 就能保留原有的样子。在字符串赋值的时候,前面加 ‘r’ 可以防止字符串被转义。以 ‘r’ 开头的字符串,常用于正则表达式,对应着 re 模块。
print(r"\nHello World")
print("\nHello World")
然后,我们先介绍两个函数:re.match() 与 re.search()。
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,就返回 None;re.search() 扫描整个字符串并返回第一个成功的匹配。
1.17.1 正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。多数字母和数字前加一个反斜杠时会拥有不同的含义。标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。反斜杠本身需要使用反斜杠转义。由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于 \\t )匹配相应的特殊字符。
1.17.2 正则表达式修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。
想了解更多的模式可参考 Python3 正则表达式。
1.18 面向对象
面向对象技术的介绍可以参考 Python3 面向对象。
1.18.1 继承
下面是一个最基本的继承:
class DerivedClassName(BaseClassName1):
<statement-1>
.
.
.
<statement-N>
假如上述例子中的 DerivedClassName 与 BaseClassName1 不在同一个作用域中,我们需要做如下修改:
class DerivedClassName(modname.BaseClassName1):
<statement-1>
.
.
.
<statement-N>
派生类继承基类的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。下面是一个最经典的例子:
# 一个 Cat 类型的对象派生自 Animal 类
class Animal:
def __init__(self, name):
self.name = name
def yell(self):
print("%s: %s" % (self.name, "..."))
class Cat(Animal):
def __init__(self, name):
Animal.__init__(self, name)
a, b = Animal("a"), Cat("b")
a.yell(), b.yell()
print(a.__class__, b.__class__)
>>> a: ...
>>> b: ...
>>> <class '__main__.Animal'> <class '__main__.Cat'>
在这个简单的例子里,Cat 继承了 Animal 的 yell() 方法,同时在构造函数里调用了 Animal 的构造函数。实际上,我们还有其他调用父类函数的方法(具体可参考代码文件)。
假如我们没有在 Cat 中重新实现 yell() 方法,Cat 将默认调用 Animal 的 yell() 方法。我们可以在 Cat 中实现与 Animal 不一样的 yell(),这就叫做方法重写。我们可以通过方法重写来实现多态。
class Animal:
def __init__(self, name):
self.name = name
def yell(self):
print("%s: %s" % (self.name, "..."))
class Cat(Animal):
def __init__(self, name):
Animal.__init__(self, name)
def yell(self):
print("%s: %s" % (self.name, "Meow"))
a, b = Animal("a"), Cat("b")
a.yell(), b.yell()
print(a.__class__, b.__class__)
>>> a: ...
>>> b: Meow
>>> <class '__main__.Animal'> <class '__main__.Cat'>
实现新的 yell() 后,Cat 调用 yell() 会输出与原先不一样的结果。
在此基础上,我们还可以实现多继承(即一个派生类同时继承多个类)。
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python 从左至右搜索:即方法在子类中未找到时,从左到右查找父类中是否包含方法。
关于多继承的问题,还可参考 多继承问题 (super 与 mro)。它解释了 super 方法的优点。
1.19 彩蛋
1.19.1 Config 模块
将代码中的配置项抽取到配置文件中,修改配置时不需要涉及到代码修改,避免面对一堆令人抓狂的 magic number,极大的方便后期软件的维护。python 本身提供标准的配置读写模块 configParse(python2,python3 修改为 configparser),用于读取 ini 格式的配置文件。
假设我们要搭建一个模型,这个模型需要用到多组不同的参数配置,使用 config 文件能让这个过程变得简单起来。
# 首先定义一个类(假设是一个模型)
class Model:
def __init__(self,
file='',
image_size=256,
batch_size=8,
num_epochs=None,
iterations=5e5,
learning_rate=3e-4,
training=True):
self.file = file
self.image_size = image_size
self.batch_size = batch_size
self.num_epochs = num_epochs
self.iterations = int(iterations)
self.learning_rate = learning_rate
self.training = training
我们假设将上述的模型保存在了一个叫 model.py 的文件中。接下来,我们需要在同一目录下创建名为 config.ini 的配置文件,里面的内容如下:
[DEFAULT]
file = default.tfrecords
image_size = 256
batch_size = 8
num_epochs = 100
iterations = None
learning_rate = 3e-4
training = true
[training]
file = training.tfrecords
image_size = 256
batch_size = 8
num_epochs = None
iterations = 5e5
learning_rate = 3e-4
training = true
[testing]
file = testing.tfrecords
image_size = 512
batch_size = 1
num_epochs = 1
training = false
当我们需要为模型配置参数时,我们可以使用以下代码来读取配置文件:
import configparser
# 创建一个新的 config parser,新创建的 parser 的 section 列表为空
config = configparser.ConfigParser()
print("Empty config: %s" % config.sections())
# 读取配置文件
config.read("config.ini")
# 拉去 section 列表时,会忽略 DEFAULT 项
print("Config sections: %s" % config.sections())
>>> Empty config: []
>>> Config sections: ['training', 'testing']
下面是一些详细的操作:
# 判断某个 section 是否存在
print("training: ", 'training' in config)
print("nothing: ", 'nothing' in config)
>>> training: True
>>> nothing: False
# 配置文件的结构与 dict 类似
for key, value in config.items():
print(key, value)
for k, v in value.items():
print(k, v)
>>> DEFAULT <Section: DEFAULT>
>>> file default.tfrecords
>>> image_size 256
>>> batch_size 8
>>> num_epochs 100
>>> iterations None
>>> learning_rate 3e-4
>>> training true
>>> training <Section: training>
>>> file training.tfrecords
>>> image_size 256
>>> batch_size 8
>>> num_epochs None
>>> iterations 5e5
>>> learning_rate 3e-4
>>> training true
>>> testing <Section: testing>
>>> file testing.tfrecords
>>> image_size 512
>>> batch_size 1
>>> num_epochs 1
>>> training false
>>> iterations None
>>> learning_rate 3e-4
# 同样可以使用下标访问
print(config['DEFAULT']['file'])
>>> default.tfrecords
接下来,我们将使用配置文件来创建模型。首先,我们需要对模型进行一些修改:
class Model:
def __init__(self,
file='',
image_size=256,
batch_size=8,
num_epochs=None,
iterations=5e5,
learning_rate=3e-4,
training=True,
config_session=None):
if config_session is None:
self.file = file
self.image_size = image_size
self.batch_size = batch_size
self.num_epochs = num_epochs
self.iterations = int(iterations)
self.learning_rate = learning_rate
self.training = training
else:
self.file = config_session['file']
self.image_size = config_session.getint('image_size')
self.batch_size = config_session.getint('batch_size')
self.num_epochs = config_session.getint('num_epochs')
self.iterations = int(config_session.getfloat('iterations'))
self.learning_rate = config_session.getfloat('learning_rate')
self.training = config_session.getboolean('training')
# 读取 training 配置
model = Model(config_session=config['training'])
print(model.file, model.iterations, model.training)
>>> training.tfrecords 500000 True
# 同样可以读取默认值
model = Model(config_session=config['DEFAULT'])
print(model.file, model.iterations, model.training)
# 读取 testing
# 由于在 testing 配置里找不到 iterations 与 learning_rate,将会从 DEFAULT 里读取相应的值
model = Model(config_session=config['testing'])
print(model.file, model.iterations, model.training)
>>> testing.tfrecords 0 False
然而,使用上述操作来读取的话,代码还是显得有点臃肿。我们有更优雅的方法来读取配置文件。我们可以使用 pyyaml 来更方便地读取配置文件。pyyaml 是 python 的三方库,需要另行安装。
假设我们想要将上述的 config.ini 转换为 yaml 格式,我们可以参考下面的代码:
config = dict()
config['DEFAULT'] = {'file': 'default.tfrecords', 'image_size': 256, 'batch_size': 8,
'num_epochs': 100, 'iterations': None, 'learning_rate': 3e-4,
'training': True}
config['training'] = {'file': 'training.tfrecords', 'image_size': 256, 'batch_size': 8,
'num_epochs': None, 'iterations': 5e5, 'learning_rate': 3e-4,
'training': True}
config['testing'] = {'file': 'testing.tfrecords', 'image_size': 512, 'batch_size': 1,
'num_epochs': 1, 'iterations': None, 'learning_rate': 0,
'training': True}
with open('config.yaml', 'w', encoding='utf-8') as f:
yaml.dump(config, f)
执行上述代码,我们可以获得一个保存着下面内容的 yaml 文件:
DEFAULT: {batch_size: 8, file: default.tfrecords, image_size: 256, iterations: null,
learning_rate: 0.0003, num_epochs: 100, training: true}
testing: {batch_size: 1, file: testing.tfrecords, image_size: 512, iterations: null,
learning_rate: 0, num_epochs: 1, training: true}
training: {batch_size: 8, file: training.tfrecords, image_size: 256, iterations: 500000.0,
learning_rate: 0.0003, num_epochs: null, training: true}
当我们需要读取 yaml 文件时,我们只需执行下面的代码:
with open('config.yaml', 'r', encoding='utf-8') as f:
# config 是一个 dict
config = yaml.load(f)
接下来,我们就可以使用 yaml 文件来初始化我们的类。读取字典中的值逐一初始化会显得有点繁琐,因此我们可以使用 __dict__ 属性来初始化。
class Model:
def __init__(self, kwargs):
self.__dict__ = kwargs
with open('config.yaml', 'r', encoding='utf-8') as f:
config = yaml.load(f)
model = Model(config['training'])
print(model.file, model.batch_size, model.num_epochs, model.training)
>>> training.tfrecords 8 None True
不过,我们最好不要只提供上述的初始化方式。因为上述的初始化方式没有在代码里提供参数的定义。下面是一种可行的改进方式:
class Model:
def __init__(self, kwargs, *,
file='',
image_size=256,
batch_size=8,
num_epochs=None,
iterations=5e5,
learning_rate=3e-4,
training=True):
if kwargs:
self.__dict__ = kwargs
else:
self.file = file
self.image_size = image_size
self.batch_size = batch_size
self.num_epochs = num_epochs
self.iterations = int(iterations)
self.learning_rate = learning_rate
self.training = training
1.19.2 命令行参数
使用命令行参数的话,我们能够使我们的模型更易于用户使用。
对于命令行参数,我们可以使用 sys 模块来获取。假设我们的代码文件如下:
print(sys.argv)
我们在命令行里执行下面的指令时,会得到以下的运行结果:
Eddie$ python3.5 tmp.py --h --i 123
>>> ['tmp.py', '--h', '--i', '123']
而 getopt 模块是专门处理命令行参数的模块,用于获取命令行选项和参数,也就是 sys.argv。命令行选项使得程序的参数更加灵活。支持短选项模式(-)和长选项模式(–)。
- args: 要解析的命令行参数列表。
- options: 以列表的格式定义,options后的冒号(:)表示该选项必须有附加的参数,不带冒号表示该选项不附加参数。
- long_options: 以字符串的格式定义,long_options 后的等号(=)表示如果设置该选项,必须有附加的参数,否则就不附加参数。
- 该方法返回值由两个元素组成: 第一个是 (option, value) 元组的列表。 第二个是参数列表,包含那些没有’-‘或’–’的参数。
下面是一个应用场合。用户能够通过命令行参数修改模型的参数:
import getopt
import sys
class Model:
def __init__(self, kwargs, *,
file='',
image_size=256,
batch_size=8,
num_epochs=None,
iterations=5e5,
learning_rate=3e-4,
training=True):
self.file = file
self.image_size = image_size
self.batch_size = batch_size
self.num_epochs = num_epochs
self.iterations = int(iterations)
self.learning_rate = learning_rate
self.training = training
for key, value in kwargs.items():
self.__dict__[key] = value
# 提取命令行参数,sys.argv[1:] 表示忽略掉下标为 0 的文件名
opts, args = getopt.getopt(sys.argv[1:], [], ['file=', 'image_size=', 'batch_size=', 'num_epochs=',
'iterations=', 'learning_rate=', 'training='])
# 创建一个参数字典
config = dict()
for k, v in opts:
# k[2:] 用于把 '--' 去掉
config[k[2:]] = v
# 新建对象
model = Model(config)
print(model.file)
Eddie$ python3.5 tmp.py --file training.tfrecords
>>> training.tfrecords