学习报告(week 1)
VITON: An Image-based Virtual Try-on Network
Getting Start
这篇文献主要介绍了一种全新的完全基于 2D RGB 图像处理的虚拟试衣技术 Virtual Try-on Network (VITON)。不同于较为传统的需要进行 3D 测量获取人体信息的技术,VITON 无需任何 3D 信息即可生成较为真实的试衣图像,这克服了 3D 技术需要较大运算量与成本的问题。
Conditional Generative Adversarial Networks (CGANs)
在无监督的 GAN 的基础上,CGAN 加上了一些限制,能让我们更好地掌控生成图片的结果。其 loss 函数为:
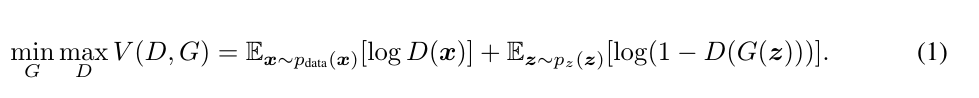 我们需要先对 discriminator 进行训练,然后再对 generator 进行训练,通过二元极小极大博弈来获得理想的结果。在原文中,作者有指出单纯使用 CGAN 来实现虚拟试衣会出现一些服饰细节的丢失 (如:logo、text)。因此,作者在使用 CGAN 的基础上,将 VITON 的实现分割为两个部分:Multi-task Encoder-Decoder Generator 与 Refinement Network。
我们需要先对 discriminator 进行训练,然后再对 generator 进行训练,通过二元极小极大博弈来获得理想的结果。在原文中,作者有指出单纯使用 CGAN 来实现虚拟试衣会出现一些服饰细节的丢失 (如:logo、text)。因此,作者在使用 CGAN 的基础上,将 VITON 的实现分割为两个部分:Multi-task Encoder-Decoder Generator 与 Refinement Network。
Multi-task Encoder-Decoder Generator
在本质上,这是一个 CGAN,它的输入是 person representation p 和 target clothing image c。
其中,p 由 3 个部分组成,分别是:Pose heatmap、Human body representation、Face and hair segment。Pose heatmap 通过计算 18 个关键点的坐标来表示一个人的姿势,而这个计算则是运用了 Part Affinity Fields。Human body representation 是通过一个 human parser 来获取一幅表示人体躯干部分的 binary mask,作者在这里直接使用了别人的基于 CNN 的一个研究成果。Face and hair segment 采用了与 Human body representation 同样的技术来获取人体的脸部与头发等信息,由于我们的目的仅是替换掉原人像中的衣服部分,我们需要脸部等部位的 RGB 信息,防止生成的图像出现一些意外的损失。最后,将这三部分结合起来,我们可以获得一个 22-channel 的 p。
但这个星期我没有足够的时间去了解这些技术,对这两个技术更深入的学习将会在以后补上。
Generator 的输出是 synthesized image I′ 与需要进行替换的人像服装部分的 segmentation mask M。到了这里,我们可以发现,作者所说的 clothing-agnostic person representation 其实是仅通过常规 CGAN 所得到的结果。 在 loss 函数上,作者选用的是比较简单的 1 范数,通过计算预测值与期望值的差的绝对值来估计网络的误差。在这里,作者直接使用了 VGG19 network 来量化图片的 visual perception,同时,为了使网络更关注服装部分,loss 函数也考虑了 mask 的误差。具体的 loss 函数如下:
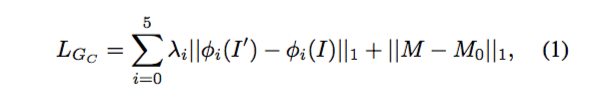
Refinement Network
在前文也提到过,单纯使用 CGAN 实现的效果很难保留一些像 logo 之类的信息,所以作者在 CGAN 上做了一个改进,加入了 Refinement Network 以把这些信息添加到生成的图像中。其实最简单的做法并非通过额外的 network 来生成最终结果,而是直接把服装的细节贴上去。但这样的做法通常会令生成的图片留有比较多的空隙,因此,我们需要使用之前获得的 M 的信息把 c 变换到我们所需要的形状 c′。使用 shape context TPS,我们可以实现这个目标。但文章似乎没有详细说明如何建立 context shape matching 所需要的特征点的映射关系,或许在代码中有提及如何对特征点进行采样,但最近我还要准备语言考试,所以代码部分的测试只能留到下一星期了。Refinement Network 的输出是一个 binary composition mask α,α用来确定 I′ 的那些像素点需要被 c′ 替代。最终的 synthesized image 为 I^,计算公式如下:
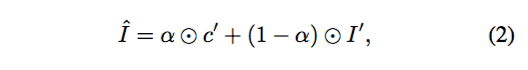 Refinement Network 的 loss 函数为:
Refinement Network 的 loss 函数为:
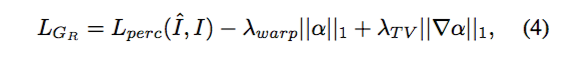 其中,第一部分与 Generator 类似,是使用了 VGG19 network 来计算的 I 与 I^ 的 1 范数误差;第二部分则是通过计算 α 来增大服装部分对生成图片的影响;第三部分通过计算 total variation loss 使图像变得平滑。
其中,第一部分与 Generator 类似,是使用了 VGG19 network 来计算的 I 与 I^ 的 1 范数误差;第二部分则是通过计算 α 来增大服装部分对生成图片的影响;第三部分通过计算 total variation loss 使图像变得平滑。
Implementation Details
在 training setup 方面,作者使用了自适应学习率的 Adam optimizer,并采用了大小为 16 的 batch size。
在 Encoder-decoder generator 中,作者分别在 encoding 和 decoding 中使用了 6 层的卷积网络。对我而言,卷积层的 filter 数与步长 stride 的选用一直都是比较玄乎的事情,而作者似乎使用了 zero-padding 来保证卷积层的输入与输出的分辨率比为 2 或 0.5。具体的网络可以参考下图:
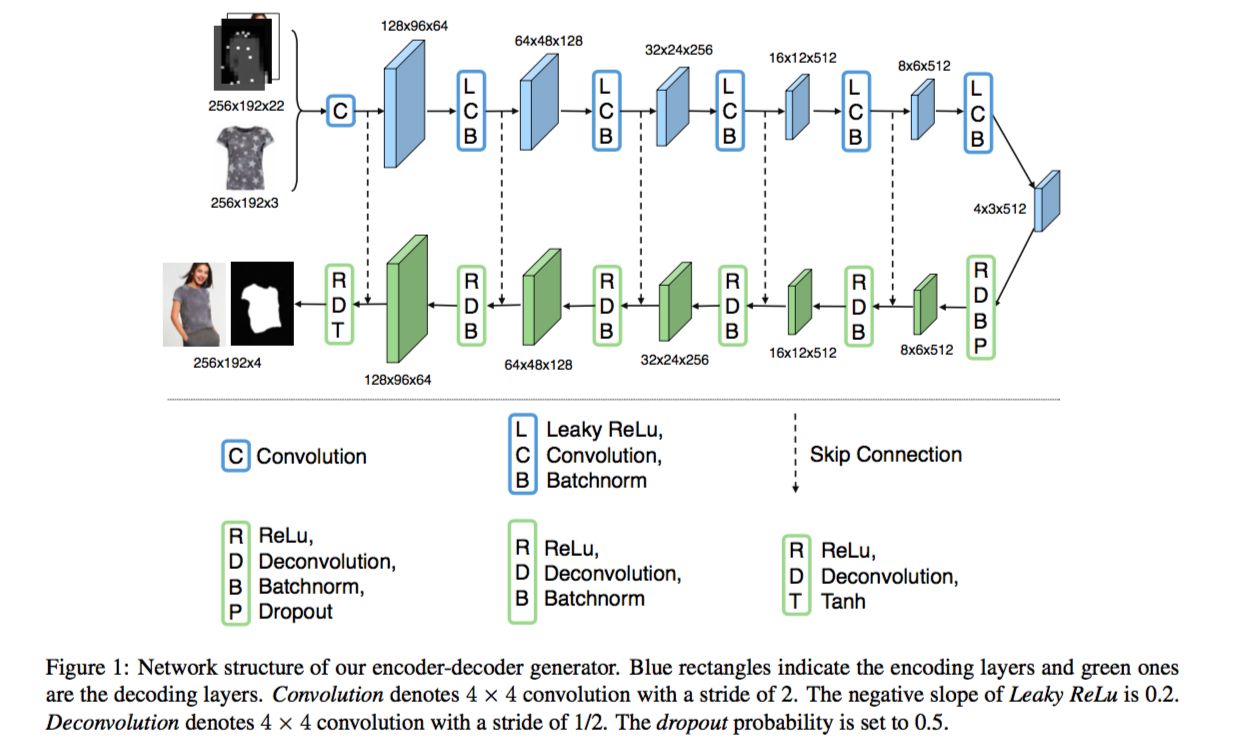 在 Encoder-decoder generator 中,作者使用了类线性的 Leaky ReLu 或线性的 ReLu 作为激活函数,生成 segmentation mask 的通道则在输出层使用了 tanh,而在 Refinement Network 中,作者也使用这两个函数作为中间层的激活函数。为了生成 binary mask,作者在输出层的最后一个通道上使用了 Sigmoid 函数。具体的网络可以参考下图:
在 Encoder-decoder generator 中,作者使用了类线性的 Leaky ReLu 或线性的 ReLu 作为激活函数,生成 segmentation mask 的通道则在输出层使用了 tanh,而在 Refinement Network 中,作者也使用这两个函数作为中间层的激活函数。为了生成 binary mask,作者在输出层的最后一个通道上使用了 Sigmoid 函数。具体的网络可以参考下图:
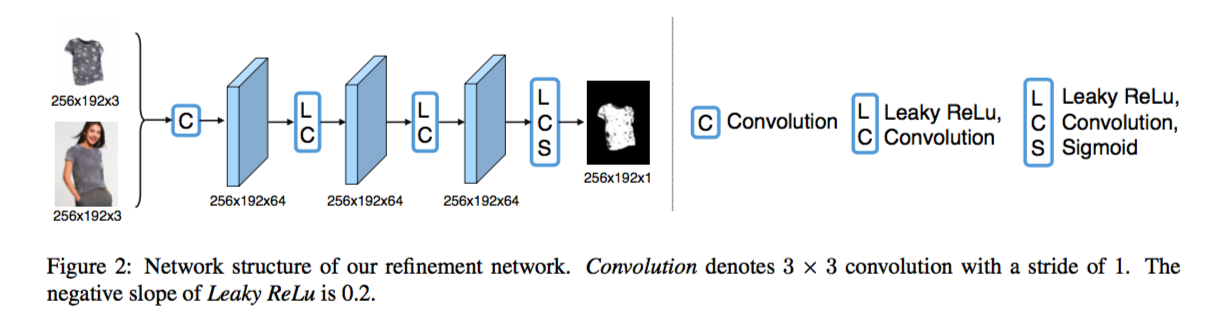
Compared Approaches
文章将 VITON 与其他的一些技术进行了对比:
- GANs with Person Representation (PRGAN)。与 VITON 相比,没有额外的 Refinement Network,具体原理和 Multi-task Encoder-Decoder Generator 相似,但在获取 person representation 时并没有考虑 Face and hair segment 的信息。
- Conditional Analogy GAN (CAGAN)。直接对人像与服装图片构造 CGAN,但由于并没有提取 person representation 信息,CAGAN 在实际测试中的效果会不太理想。
- Cascaded Refinement Network (CRN)。不使用对抗网络,直接通过构造多层的 CNN 来获得结果。
- Encoder-decoder generator。 VITON 第一阶段的输出,碍于普通 CGAN 的限制,获得的图像会丢失 logo 等细节信息。
- Non-parametric warped synthesis。不使用 Refinement Network,直接将拉伸后的服装图片贴到原人像上,跳过了学习的过程会使生成的图片留有很多空隙。

Qualitative Results
作者提及了一些导致 VITON 失效的情况。
首先提到的是 neck artifact 的问题,这是指,在一张服装图片中,我们通常可以看到颈部位置的尺码标签,而实际试衣时,这部分的布料将会被人体遮挡住。在完全基于 2D 图像处理的 VITON 上,由于缺少 3D 深度信息,如果直接将这样的图片作为输入的话,生成的图片会留有严重的缺陷。为了解决这一问题,作者最初训练了一个 FCN(Fully Convolutional Network) model 来对作为输入的服装图片进行预处理,以去除尺码标签对生成的图像的影响。
 之后提到的是保留原人像图片中裤子部分信息的方法,作者提出的一个解决方案为,对裤子的部分采用与 Face and hair segment 相同的处理。通过改进 human parser 来解决裤子问题的同时,作者也成功使用 human parser 解决了上述的尺码标签问题。
之后提到的是保留原人像图片中裤子部分信息的方法,作者提出的一个解决方案为,对裤子的部分采用与 Face and hair segment 相同的处理。通过改进 human parser 来解决裤子问题的同时,作者也成功使用 human parser 解决了上述的尺码标签问题。
 最后提到的是目前尚未解决的失效问题,这包括原人像姿势过于特别的情况与原人像服装与要试穿的服装形状相差过大的情况。
最后提到的是目前尚未解决的失效问题,这包括原人像姿势过于特别的情况与原人像服装与要试穿的服装形状相差过大的情况。

Quantitative Results
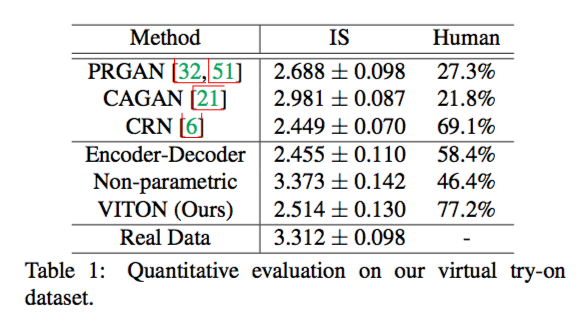
作者使用了 Inception Score 和 Perceptual user study 来评估生成图片的质量,但因为我对这一方面知识的了解并不多,我无法对这些数据进行评价,在此只能附上数据表:
Toward Characteristic-Preserving Image-based Virtual Try-On Network
Getting Start
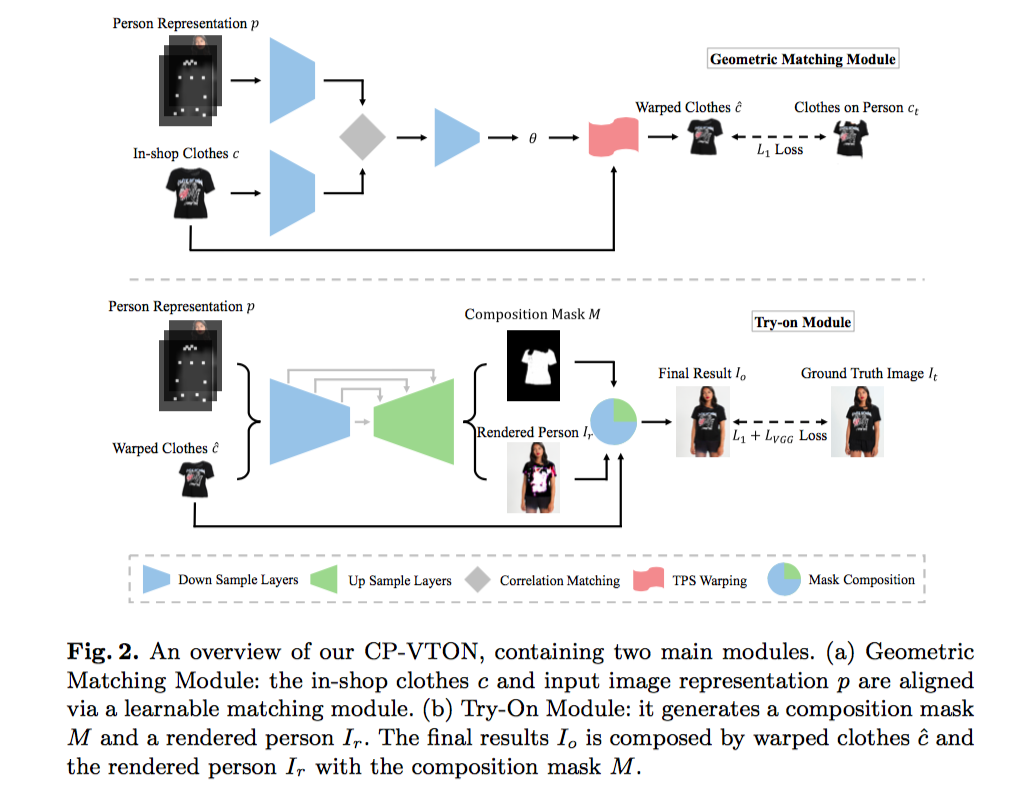
这篇文献是对 VITON 的一个改进,介绍的是一种名为 Characteristic-Preserving Virtual Try-On Network (CP-VTON) 的技术。相较于 VITON,CP-VTON 在生成试衣图像时并没有采用 shape context matching,而是采用了一种 tailored convolutional neural network。 接下来将记录一些 CP-VTON 与 VITON 不同的地方。
Geometric Matching Module
它的输入依然是 person representation p 和 target clothing image c。但与 VITON 的 Encoder-Decoder Generator 不同,Geometric Matching Module 的输出并不是一幅 segmentation mask,而是 warped clothes c^。Geometric Matching Module 通过训练一个 regression network 并使用 Thin-Plate Spline (TPS) transformation 来生成 c^,其代价函数为 c^ 与预想值 ct 的 1 范数差。在考虑 visual perception 的时候,CP-VTON 并没有使用 VGG19,而是直接使用了像素对像素的误差。毫无疑问,这种做法能提升网络的效率,但实际效果其实是比较玄乎的,很难判断用那种 loss 可以获得更好的生成效果。具体的 loss 函数公式如下:
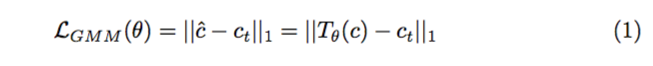
Try-on Module
和 VITON 的 Refinement Network 是大同小异,在我看来,具体的不同是在于代价函数的选择,其 loss 函数如下:
在 VITON 中,代价函数只用了 VGG19 来表示 visual perception,而在 CP-VTON 中,作者加上了 pixel-wise 的 L1 loss,而这种做法是参考 Johnson, J. et al. 的论文所得的。且外,由于 CP-VION 在 Geometric Matching Module 中并没有得到一幅 segmentation mask,在计算 Composition Mask 的误差的时候无法照搬 VITON 的 loss 函数。作者直接使用了 1 - M 的 1 范数来增强服装部分像素点对 loss 函数的影响。具体的 loss 函数如下:
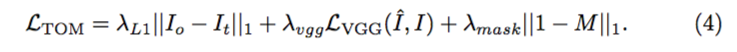
Implementation Details
首先附上网络的结构图:
 实际上,这一部分也与 VITON 的参数没太大区别,在 training setup 方面,作者将 batch size 改为了更小的 4,但这可能会导致网络的运算速度变慢。
实际上,这一部分也与 VITON 的参数没太大区别,在 training setup 方面,作者将 batch size 改为了更小的 4,但这可能会导致网络的运算速度变慢。
在 Geometric Matching Module 方面,主要分为 Feature Extraction Network 和 Regression Network 两部分。在 Feature Extraction Network 部分中,文章貌似没有提到 filter 的维数,在最后前四层卷积层中使用 2 作为步长,在最后两层使用了 1 作为步长以维持输出的维数。Regression Network 包含两个 2-stride 的卷积层、两个 1-stride 的卷积层、一个 full-connected 的输出层。文章也给出了 SCMM 与 GMM 的效果对比,我认为 GMM 在处理较大幅度的变形的时候能获得比 SCMM 更好的效果。
 Try-On Module 使用了一个类似于 VITON Encoder-Decoder Generator 的网络结构,这里就不赘述了。
Try-On Module 使用了一个类似于 VITON Encoder-Decoder Generator 的网络结构,这里就不赘述了。
Qualitative Results
依然没有解决 VITON 在遇到 rare poses 与 massive shape difference 时的缺陷。但奇怪的地方是,CP-VTON 没法解决 neck artifact 的问题,在原论文里似乎通过改进 human parser 解决了这个问题,而同样用到 person presentation 的 CP-VTON 却没有解决这个问题。

Quantitative Results
CP-VTON 在评估网络的性能时采用了与 VITON 不同的方法,CP-VTON 将测试集按特征的丰富程度分成了 LARGE 与 SMALL 两组。通过分析数据,我们可以发现 CP-VTON 在处理 SMALL 的时候的效果是不如 VITON 的,但在处理 LARGE 时则能得到比较大的提升。
 结合文章中的图片,按照我的理解,我认为可能的原因是训练时并没有加入 TV norm,以致生成的图片不够光滑。
结合文章中的图片,按照我的理解,我认为可能的原因是训练时并没有加入 TV norm,以致生成的图片不够光滑。

Conclusion
总的来说,我觉得 CP-VTON 是对 VITON 的一个不错的改进,虽然在处理简单的情况时不如 VITON 的表现好,它在处理特征比较丰富的服装或者较大幅度的形变时,能得到比 VITON 出色不少的结果。而我认为对 CP-VTON 比较容易实现的提升在于增强生成图片的光滑度以提升处理简单情况时的效果、仿照 VITON 解决 neck artifact 的问题;比较难的方面就在于继续提升 GMM 的效果。在我看来,SCMM 得出来的特征点映射在正常情况下还是要优于 GMM 的。但由于 SCMM 在处理大幅度形变的性能不佳,为了使网络的效果更稳定,GMM 成为了目前更好的选择。这一周主要了解了一下两个试衣网络的结构,在下周会抽空把代码部分的学习补上。