学习报告(week 2)
Fashion Style Generator
Getting Start
这篇文献主要介绍了一种图像风格迁移问题,在这里,作者介绍了一种全新的 GAN,通过这个 GAN,我们能够将一幅风格图片的风格迁移到一件时尚单品上,与此同时,我们能够保留原有服饰的形状与部分的设计。 Fashion Style Generator 由两部分构成,这两部分分别是 Image Transformation Network 与 Discriminator Network。其实早在之前,图像风格迁移问题就已经有比较出色的研究,但是 Gatys 等人的研究主要关注的是图像的 global structure,这无法避免原图像细节的丢失,所以显然不适用于 fashion style 问题。相对的,Li and Wand 的研究将输入图片切割成了若干个 patch,从而保留更多细节上的信息。然而,在缺少额外的全局信息的指导下,我们很难保持原图像的大致形状。在这个基础上,作者结合了以上两种方法的优点,同时考虑了 global 与 local 的 loss,以能实现保留原有服饰的形状与部分的设计的风格迁移。
Discriminator Network
虽然要处理的原图像是从 Image Transformation Network 输入的,但基于 GAN 需要先对 Discriminator 进行训练,我们在此先介绍 Discriminator 的具体信息。首先,鉴别器的代价函数 L 是 patch-based loss L1 与 global-based loss L2 的加权组合,之后我们将分别对 L1 与 L2 进行讨论,而 L 的具体公式如下:
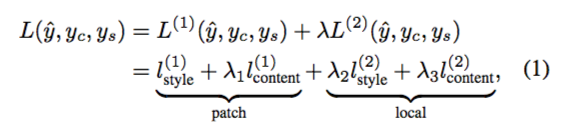 到目前为止,我需要先指出一个问题,在原文提供的公式中,L2 被标记为 local,而在上文,作者明确地提到 L2 是 global-based loss,且外,通过之前的阅读,我们也可以发现 local 是与 patch 相匹配的描述。因此,我怀疑此处是作者一个挺不走心的错漏,在之后的讨论中,我也会指出一些疑似的纰漏。
到目前为止,我需要先指出一个问题,在原文提供的公式中,L2 被标记为 local,而在上文,作者明确地提到 L2 是 global-based loss,且外,通过之前的阅读,我们也可以发现 local 是与 patch 相匹配的描述。因此,我怀疑此处是作者一个挺不走心的错漏,在之后的讨论中,我也会指出一些疑似的纰漏。
L1 与 L2 都有各自所对应的 content loss 与 style loss。
对于 L2,content loss 服务于保留原服饰图像的信息,它是原服饰图像 yc 与输出 y^ 的 perceptual similarity 的欧氏距离,其中 perceptual similarity 可以通过 VGG-19 的研究成果得到,而公式中的分母显然是图像的 number of elements,即 通道数 x 高度 x 宽度,具体公式如下:
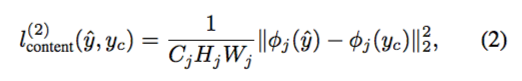 style loss 是风格图像的损失,对于 L2,style loss 提取了图像的 Gram matrix 来度量图像风格,其公式为原图像与生成图像的 Gram 矩阵的 F-范数,也可以将其理解为高维度的欧氏距离,具体公式如下:
style loss 是风格图像的损失,对于 L2,style loss 提取了图像的 Gram matrix 来度量图像风格,其公式为原图像与生成图像的 Gram 矩阵的 F-范数,也可以将其理解为高维度的欧氏距离,具体公式如下:
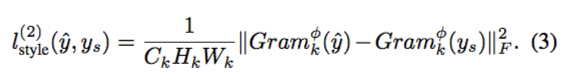 而对于 L1 的 content loss,作者只是使用了一个比较常规的欧氏范数作为代价函数,且作者同样用到了 VGG-19 的成果来量化 patch images 的相似度,其公式如下:
而对于 L1 的 content loss,作者只是使用了一个比较常规的欧氏范数作为代价函数,且作者同样用到了 VGG-19 的成果来量化 patch images 的相似度,其公式如下:
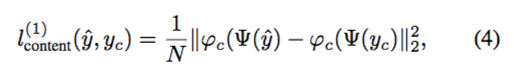 但我们可以注意到,作者在这条公式中漏掉了两个括号,这种程度的错误让我觉得非常费解。按照我的理解,上述公式应该可以表示成如下形式:
但我们可以注意到,作者在这条公式中漏掉了两个括号,这种程度的错误让我觉得非常费解。按照我的理解,上述公式应该可以表示成如下形式:
 由于我目前对 VGG-19 还不是很了解,我可能会弄错一些细节上的东西,但我猜测将以下公式作为 L1 content loss 可能会更好:
由于我目前对 VGG-19 还不是很了解,我可能会弄错一些细节上的东西,但我猜测将以下公式作为 L1 content loss 可能会更好:
 至于 L1 style loss,因为目前并没有 pretrained 的计算 patch style loss 的网络,作者训练了一个 GAN 并且使用了 Hinge loss 作为代价函数,其中 si 为第 i 个 patch 的分类分数,具体公式如下:
至于 L1 style loss,因为目前并没有 pretrained 的计算 patch style loss 的网络,作者训练了一个 GAN 并且使用了 Hinge loss 作为代价函数,其中 si 为第 i 个 patch 的分类分数,具体公式如下:
 根据我目前的知识,使用 Hinge loss 需要让预测值尽可能在 [-1, 1] 之间,以避免分类器过度自信。而作者是直接引用了之前所提到的 Li and Wand 的研究中的做法,具体的优劣我也暂时没时间去考究了。但我在这里提出一个猜想,或许我们可以求出每个 patch image 的 Gram matrix,并使用 VGG-19 的成果(或者参考其方法自行训练)来获得 patch style loss。
根据我目前的知识,使用 Hinge loss 需要让预测值尽可能在 [-1, 1] 之间,以避免分类器过度自信。而作者是直接引用了之前所提到的 Li and Wand 的研究中的做法,具体的优劣我也暂时没时间去考究了。但我在这里提出一个猜想,或许我们可以求出每个 patch image 的 Gram matrix,并使用 VGG-19 的成果(或者参考其方法自行训练)来获得 patch style loss。
Image Transformation Network
在这一个网络中,Image Transformation Network 作用为一个 Fashion Style Generator,在这里我们简称它为 G。G 是一个典型的 Convolutional Encoder-Decoder Network,它的输入是风格图像 ys、原服饰图像 yc2、与原服饰图像对应的若干 patch 图像 yc1,它的输出是合成图片 y^。在 Encoder 部分,作者直接使用了 VGG-19 网络来进行编码(我已经在好几篇论文中有留意这个 VGG-19 了,因此有必要在有空一点的时候去深入了解一下关于它的研究),考虑到这部分的内容来源于已有的 pretrained 网络,这里就暂时不对其进行分析了。显然,在这里,Encoder 不是最重要的部分,因为在整个训练过程中,这部分的参数将不做任何改变。我们需要用到之前训练所得的 Discriminator 来对 Decoder De 的参数进行优化,这里用到的目标函数也是经典的 GAN 目标函数:
 需要注意的是,作者并没有训练 Encoder,因此,GAN 目标函数中的 z 应该被替换成 Encoder 的输出(我是这么理解的,但是作者为什么要用 VAE 的输出呢?T^T)。
需要注意的是,作者并没有训练 Encoder,因此,GAN 目标函数中的 z 应该被替换成 Encoder 的输出(我是这么理解的,但是作者为什么要用 VAE 的输出呢?T^T)。
作者在学习 patch style network 的时候已经同步初始化好了一组 De 的参数了,这时我们需要使用 back-propagation 来更新参数 θ 的值。但在这里,我遇到了一个让我费解的问题,在执行 BP 算法的时候,η 作为学习率,作者使用了如下的公式:
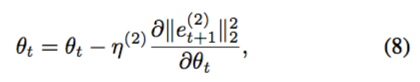
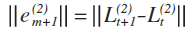 不同于一般的分类问题,这里我们不能使用预测类标与实际类标的最小二乘作为误差,而作者这里却用了两次不同的外循环的 L 的最小二乘作为误差。首先,我的第一个问题是作者如何获得下一个循环的代价 Lt+1;第二个问题则是貌似使用 Lt 的二范数作为误差会更合理。我希望有空的时候可以和老师探讨一下这个问题。
不同于一般的分类问题,这里我们不能使用预测类标与实际类标的最小二乘作为误差,而作者这里却用了两次不同的外循环的 L 的最小二乘作为误差。首先,我的第一个问题是作者如何获得下一个循环的代价 Lt+1;第二个问题则是貌似使用 Lt 的二范数作为误差会更合理。我希望有空的时候可以和老师探讨一下这个问题。
由于 patch 部分的 BP 也使用了与 global 一样的处理,这里就不再赘述了,最后附上算法的伪代码:

Experimental Details
作者从 chictopia 获得了一个 Fashion 144k dataset 作为原服饰图像输入,从 Hadi Kiapour et al. 的研究获得了一个 Online Shopping dataset 作为 patch 图像的输入,并自己从网购网站获取了 100 个样本作为测试集。接着,作者介绍了一下输入图像的维度,但与前文矛盾的是,作者声称自己是使用大小为 16 的步长从原服饰图像中获得对应的 patch 图像,而不是从 Online Shopping dataset 中获取。
然后,作者介绍了他对 VGG-19 网络的选用,介绍了他具体选用了哪些层,因为我自己对 VGG-19 也不是很了解,这里就不将其复述一遍了。作者提到,他使用了 batch normalization 与 leaky ReLU 来提升网络的效果。其中,batch normalization 能通过标准化操作加大梯度,从而使模型收敛得更快;leaky ReLu 则是单纯避免负值的出现。
剩下的也是一些调参的工作,这些参数与 De 有关,iteration 与 batch size 之类就没什么分析的意义了,至于使用了学习率为 1e-3 的 Adam 则是为了让网络更容易收敛。
Compared Methods
- NeuralST:即之前提到的 Gatys 等人所实现的比较出名的图像风格迁移问题的研究成果,它主要被用于模仿一些画家的风格,它确实地保留了原服饰的特征,但却没有很好地还原 style 图片的细节。对于一个 global 的方法,细节的丢失看来是不可避免的。
- MRFCNN:作者所主要参考的一个 patch-base 模型,与 NeuralST 相反,patch 的使用导致了全局信息的丢失。
- FeedS:这应该是一种时间复杂度较低的模型,它是对 Gatys et al. 研究成果的一个 adaptation。但显然,在这个问题上,效率的提升将舍弃了质量的保证。
- MGAN:Li and Wand 在 MRFCNN 基础上的一个改进,其实作者的 patch style loss 正是参考了这个研究,因此,从效果上来说其实和作者的研究没太大区别。
- FSG:作者的方法,由于考虑到了全局误差,效果比 MGAN 有略微的提升,但我估计时间复杂度是要比 MGAN 高的。考虑到这个网络是 pretrained 的,这点时间成本的提高还是可以接受的。
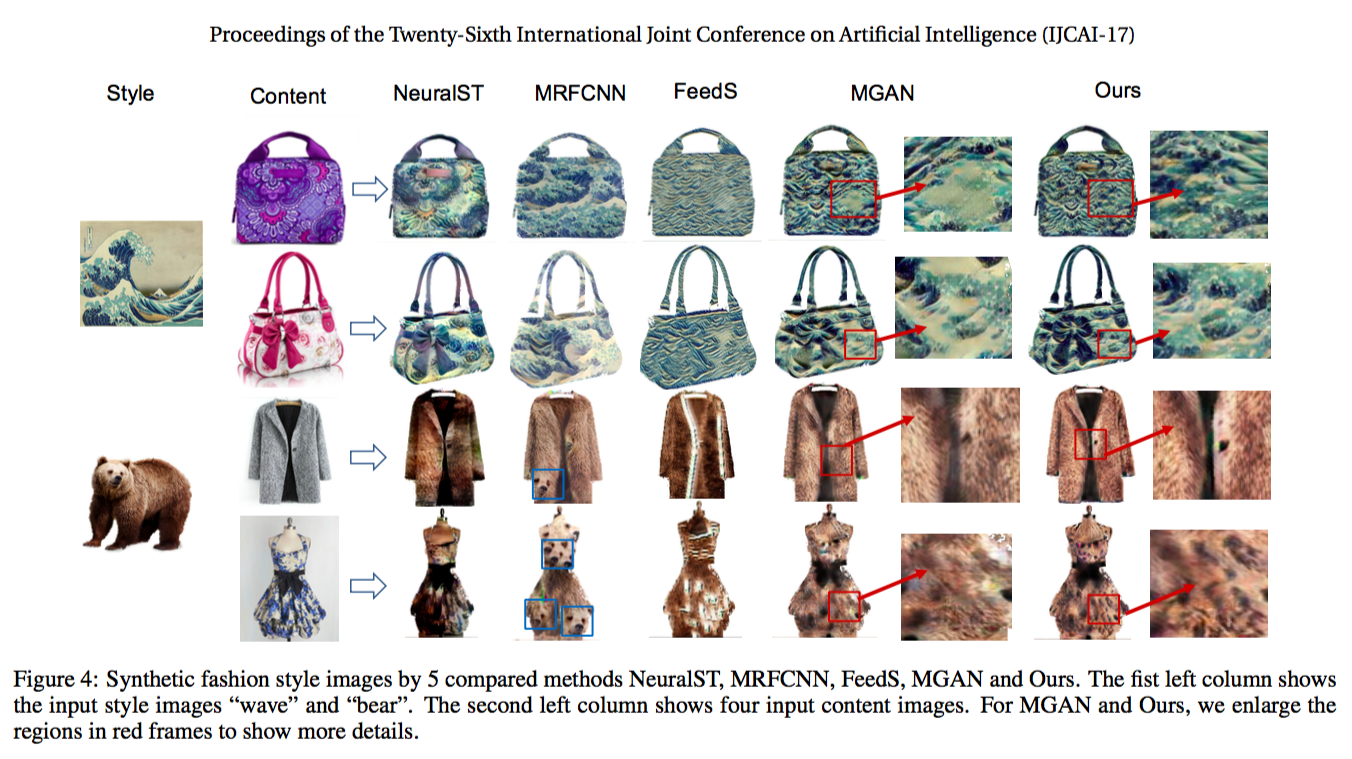
Experimental Results
作者在 single GTX Titan X GPU 上训练了 7 小时左右,其中 initialization 需要 5 小时,optimization 需要两小时。接下来介绍的是一些比较玄学的调参过程,而作者的结论是 “the patch loss plays an more important role than global loss”。
作者也提到了模型的限制。首先,因为与 MGAN 有很多相似之处,模型会在原服饰图片大面积缺少明显的纹理时失效。而这也是可以理解的,因为在这种情况下,迁移 style 时,patch content loss 会非常大。我估计作者原先想表达的是 non-texture and plain,而实际上写的却是 pain。第二种失效情况是,有时,网络会保留原服饰图像的颜色。这显然与 content loss 有关,但作者并没有给出失效时的具体信息,因此也无法进行分析。最后,输出图像的分辨率会比原图像低,但貌似这也是卷积网络中无法避免的问题。
Conclusion
总的来说,这个研究所展现的效果还是挺不错的,但文章中貌似有不少出错的地方。我能想到的一些潜在改进之处只有 patch style loss 的计算与 BP error 的计算。主要是这星期就要考试了,实在抽不出太多时间来仔细研究论文,等考试过后,一定会努力一点补回这段时间欠下的工作量 QAQ。