学习报告(week 3)
Very Deep Convolutional Networks for Large-Scale Image Recognition
Getting Start
这篇文献发表于 ICLR 2015,其研究成果 (在下文中简称为 VGG,即 Oxford Visual Geometry Group) 在 ILSVRC 2014 的图像定位 (localization) 与图像分类跟踪 (classification tracks) 任务上分别取得了第一名和第二名的好成绩。在此之前,主流的研究成果为 AlexNet,而 VGG 最重要的创新在于强化了网络深度 (depth) 的重要性。不同于以往的研究,VGG 并没有使用较大的卷积核,而是通过使用多个较小的卷积核来得到同样的感受野 (receptive field,即一个像素点能反映的原图像的信息数量)。这样的操作不仅仅减少了网络中参数的数目,还被证明能有效地提升网络的表现。且外,ILSVRC 2014 分类任务的第一名 GoogLeNet 也是通过增加网络的深度来获得更优秀的表现,但 VGG 在其他识别任务中表现出了更好的泛化能力。
最开始阅读这篇文献的原因是考虑到在之后的项目中,很有可能会运用到 VGG 的研究成果,想加深一下对这个网络的认识,以便能更好地把它运用到自己的项目中,但在阅读过后,我发现这篇文献有很多值得学习的地方。因此,这次的实验报告将会写得比以往的长,希望能藉此加深对这方面知识的印象。
ConvNet Configurations
Architecture
VGG 在训练过程中的输入是一个 224x224 的 RGB 图像。VGG 执行的唯一的预处理是,对于每个像素点,分别在 RGB 三个通道上减去对应通道的均值 (mean),这是一个类似于 Z-score 归一化的操作。但是, VGG 并没有在此基础上除以标准差 (standard deviation) 来对数据进行归一化,这样的操作能否带来更好的表现是无法通过理论进行分析的,但这能为网络带来非常微小的时间复杂度的优化。在网络的一系列卷积层中,VGG 多数使用的是 3x3 的卷积核 (这是因为 3x3 的卷积核是可以区分左右、上下、中心的最小的卷积核尺寸。其实道理很简单,考虑一维的情况,只有奇数维度才能区分出中心,而最小的奇数 1 不能区分上下或左右,所以 3x3 是最小的选择)。在其中一组配置中,VGG 使用了 1x1 的卷积核,而这就相当于对原矩阵执行了一个线性变换 (在执行完一个线性变换后,网络会执行非线性变换)。如果不考虑训练的话,我们实际上可以用一个 3x3 的卷积核来获得一个 3x3 卷积核和一个 1x1 卷积核共同作用的效果,因此,1x1 卷积核的引入能直观地反映出网络深度对网络表现产生的影响。卷积操作的步长 (stride) 被设置为了 1,则我们可以用如下公式来计算出卷积操作的输出的尺寸:
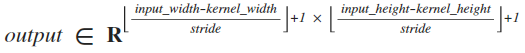
在考虑 1x1 的卷积核时,我们可以保证输出的尺寸是与输入一致的;但在考虑 3x3 的卷积核时,我们需要执行一个大小为 1 的填充 (padding,即用 0 来扩充输入的尺寸,在边缘填充一圈值为 0 的像素点,大小为 1 的 padding 能让输入的长和宽都增加 2,代入公式中刚好与 3x3 卷积核的影响抵消。其实这是一个很简单的概念,但在这一次报告就尽可能地写详细一点吧),以保证输出尺寸与输入一致。在我看来,保持输入与输出尺寸的一致是为了能对深度卷积网络中每一层的维度有更好的掌控,通俗地讲,即在卷积层浓缩特征,并仅在池化层对特征进行采样。此处使用的是极大值池化 (max-pooling,即对数据进行下采样,只保留若干特征值中最大的一个。在这里,使用 max-pooling 能保留下最强的特征且不改变特征的位置,无形中对特征进行了选择),因为采样窗口的边长等于步长,两次不同的采样不会有相交 (overlap) 的部分。
紧接在一系列卷积层之后的是三个全连接层 (fully-connected layer,全连接层一般用于高度提纯特征,将图片转换为概率或者是类标,然后交给分类器或者回归。这里的三层全连接层的大小分别是 4096、4096、1000,其中 1000 即类别的数目。实际上,使用全连接层的代价是非常高的,我们要对每一个输入配置一个与其等大小的卷积核,考虑大小为 4096 的全连接层,假设输入数目为 n,输入的维度为 axb,我们需要用到 nxaxbx4096 个 weight参数与 4096 个 bias 参数),在不同深度的 VGG 网络中,全连接层的配置都是一样的。其实,在最近的研究中也有使用全局平均池化 (global average pooling,即使用一个与窗口与图像等大小的均值池化层来代替全连接层,在这里,我们可以用 GAP 代替第一个 FC,然后再对 GAP 的输出进行全连接操作,但是使用 GAP 可能会是收敛速度变慢),但如果用 GAP 来代替 FC 对 VGG 的表现的影响还是无法确定的。之后,VGG 将全连接层的输出通过一个 softmax regression 层进行分类。
VGG 网络的所有隐层都使用了 ReLU 作为激活函数,但并没有像 AlexNet 一样使用了局部响应归一化 (Local Response Normalisation,它对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。其实我不是很懂 LRN 层的原理,它的公式还是蛮复杂的,考虑到 LRN 好像并不能提升网络表现,所以没有仔细地学习它的详细内容)。随后,VGG 通过对比使用了 LRN 与没有使用 LRN 的网络的表现,总结出 LRN 实际上并不能提升网络的表现。
Configuration
在这篇文献中,作者一共对 A 到 E 共五种卷积网络 (不包括 LRN 对比网络) 进行了评估。在这些卷积网络中,它们的深度由最小的 A (8 个卷积层加 3 个全连接层) 递增到最大的 E (16 个卷积层加 3 个全连接层)。此外,卷积层的通道数也将从 64 开始逐渐增加,最后达到 512 (每经过一个池化层,卷积层的通道数乘 2,卷积层的通道越多,输出的特征图越多)。A 到 E 的具体配置可见下图,其中,A 与 A-LRN 可视为对比实验,以论证 LRN 对网络表现并无提升:
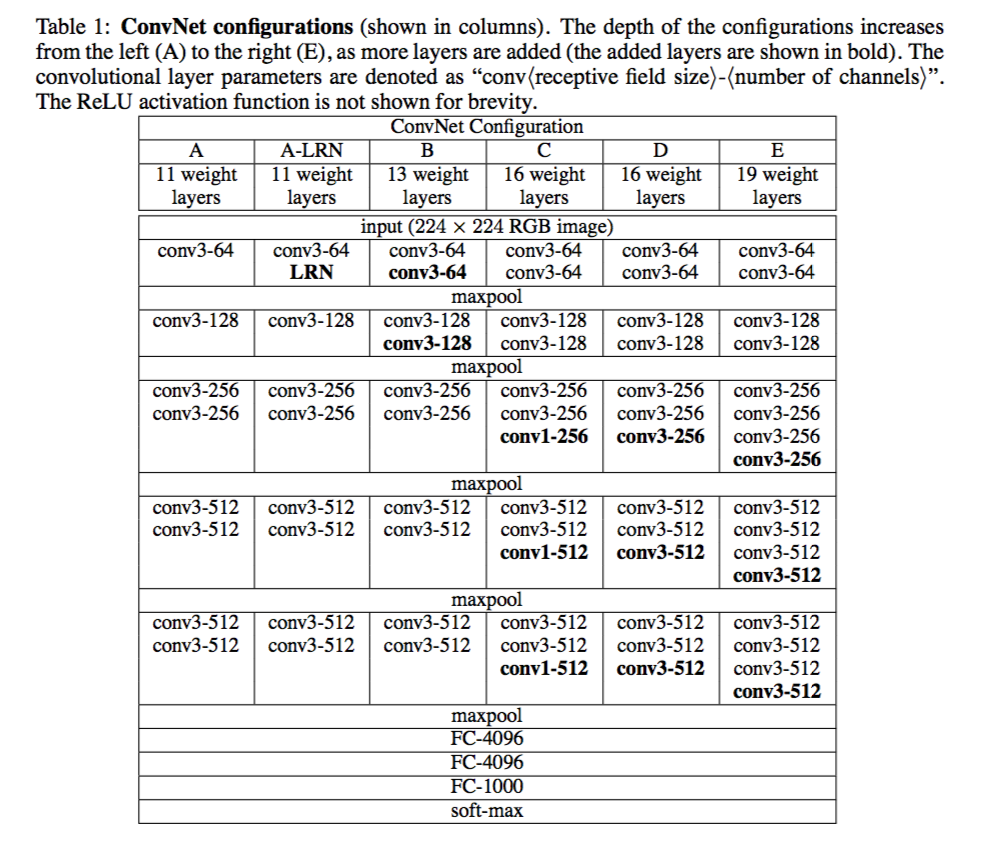
在下图,我们可以看到,不同配置的 VGG 所需的参数的数目,根据作者所述,虽然 VGG 的深度较大,但它所需的参数数目并不会比其他功能类似的网络多。

Discussion
其实关于 Configuration 的一些细节在上文也已经提到过了,这里就简略地概括一下这部分的内容:
- VGG 并没有像 ILSVRC 2012 与 ILSVRC 2013 的获奖项目一样使用较大的卷积核来获得较大的感受野,取而代之的是用一系列的较小的卷积核来获得较大的感受野。比如,3 个 3x3 的卷积核能获得的感受野与 1 个 7x7 的卷积核获得的感受野一样,如果输入输出的通道数都是 C,而前者需要用到的参数数目为 27C^2+C,后者则需要 49C^2+C。
- 在作者看来,使用 1x1 的卷积核可以在不影响感受野的情况下增强决策函数的非线性。
Classification Framework
Training
VGG 的训练过程参考了 Krizhevsky 等人的研究成果,作者使用带动量 (momentum,通俗地讲,动量能积攒历史的梯度,若当前时刻梯度与历史梯度相近,则当前的趋势会被加强;否则,当前的趋势会被抑制。使用 momentum 能加快学习速度,并且避免因学习率过大导致的无法收敛) 的小批量梯度下降 (mini-batch gradient descent,它最大的优势在于能加快收敛并且避免达到局部最优,但在这里,使用 mini-batch 还为并行计算提供了可能性) 来优化多类别逻辑回归问题 (multinomial logistic regression)。其中,batch size 为 256,momentum 为 0.9,同时加入了 weight decay (L2 正则化,用以约束 weight,此处取值为 5e-4) 与 dropout (这里的 dropout ratio 为 0.5,即训练只有半数隐层单元的神经网络) 以避免过拟合的问题。学习率 (learning rate) 的初始值为 1e-2,作者使用了 adaptive 的方法,在交叉验证集的准确率停止提升时,学习率将缩小为原来的 1/10,避免无法收敛的现象。
整个训练耗时 370K iterations (74 epochs),尽管 VGG 的参数数目和深度都比 Krizhevsky 等人的研究成果要大,但实际所需的 epoch 数却更小。这里,作者提出了对此的两个猜想:1) 更深的网络深度与更小的卷积核尺寸无形中为网络增加了正则化效果 (我懂这句话的意思,但是不懂原理 QAQ);2) 在某些层中执行了预初始化。
对于上面提出的第二个猜想,作者实际上是执行了一个很聪明的操作,作者先用随机的初始参数来对深度最小的 A 网络进行训练,此时的训练速度无疑会比较慢。然后作者把训练好的 A 的参数用作其余网络的初始化参数 (由于不同网络的深度不一样,作者只在每个网络的前四个卷积层与全连接层上使用了 A 的参数进行初始化)。虽然不同网络的深度不一样,但是它们要完成的任务是一样的,因此,A 网络的参数很有可能与其他网络的参数相近,那么使用 A 的参数对其他网络进行初始化就很有可能能加快训练速度。VGG 用 mean = 0 且 variance = 1e-2 的正态分布来对 weight 随机初始化,并将所有 bias 的初始值设成 0,而这也是一个比较常规的初始化操作。作者也提到了在论文发表后,他们发现了可以使用 Glorot & Bengio 等人的随机初始化流程来代替他们之前使用的预初始化操作。作者并没有对此进行深入讨论,但在完成自己的项目时,Glorot & Bengio 的这个成果可能能给我提供不少帮助。
为了扩充训练集,作者首先将图片 rescale,并将 rescale 后的图片 crop 成 224x224 的输入图片。且外,作者还对图片进行了随机水平翻转与 RGB 颜色变换来进一步扩充数据集。VGG 首先对训练集的图像进行各项同性缩放 (isotropically-rescaled,可以理解成缩放的时候不对图片进行扭曲,与之相对的各向异性缩放将无视原图像长宽比进行缩放),然后记缩放后的图像最小边为 S (在这里,我认为作者是将原图像缩放成正方形,然后再截取出 224x224 的部分作为卷积网络的输入)。如果最小边 S 等于 224,那么使用 224x224 的 bounding box 截取出来的图像将是原缩放图像本身;若最小边远大于 224,那么截取出来的图像则是原缩放图像的一小部分。
对于图片的缩放操作,作者采取了两种不同的方案。第一种是固定上文提到的 S 的值,分别让其等于 256 和 384 来进行两次训练。第二种是使用图像尺度抖动 (scale jittering,即令缩放得到的图像的最小边的值在 Smin 与 Smax 之间,考虑到实际输入的图片可能有不同的尺寸,在训练时输入不同尺寸的图片显然能提升网络的表现)。为了使网络的收敛加快,作者也用到了前面训练 single-scale model 时获得的参数来对 multi-scale model 进行微调 (fine-tuning,用其他模型训练好的参数来对自己的模型进行初始化,让初始参数处于较好的位置)。
Testing
论文考虑了两种预测方式,第一种是 multi-crop,第二种是 densely。所谓 multi-crop 即对缩放后获得的图像进行随机裁剪,然后通过网络对每一个裁剪出来的样本进行预测,最后求均值获得完整图像的预测值。而 densely 即不进行裁剪,直接将缩放后的图像作为网络的输入,同时,将网络中的全连接层改为卷积层。对比起 multi-crop,densely 避免了 multi-crop 存在的重复运算 (应该是不同的 crop 有重叠部分的意思) 的问题。且外,multi-crop 使用的是 zero-padding,而 densely 使用的是 neighbouring-padding (这样的操作能增大执行卷积时的感受野)。为了获得更好的效果,VGG 将原图和水平翻转后的图像的得分的均值作为最终的得分。在我看来,除了上面提及的在 testing 时的速度提升,把全连接层去掉是肯定可以提升网络 training 时的速度。虽然作者说他们认为 multi-crop 的额外运算量并不能确保获得更好的准确率,但是 VGG 最好的表现是结合 multi-crop 与 densely 而得到的。
Implementation Details
作者使用了 C++ Caffe toolbox 来运行他们的网络,这个 toolbox 能支持并行计算的功能 (近年来,用 py 貌似会主流一点)。作者提到了可以进行针对 batch 或针对 layer 的并行计算来提升速度。
Classification Experiments
作者的成果是基于 ILSVRC-2012 dataset 的,这里就不对这个数据集进行描述了。
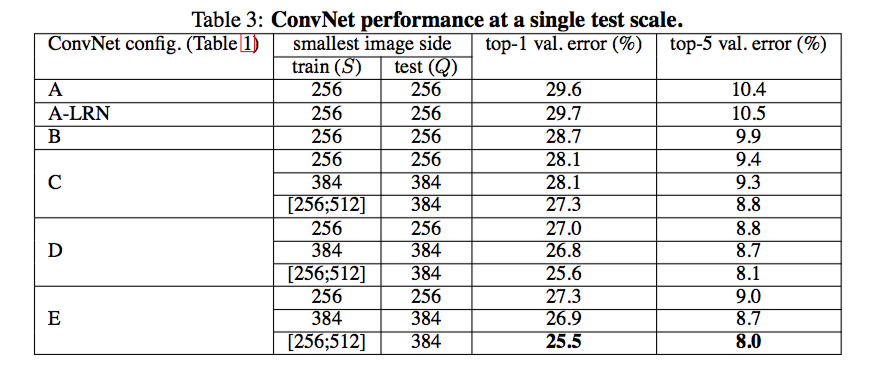
Single-Scale Evaluation
根据 single test scale 的结果,我们可以发现深度和感受野的大小会对结果产生影响 (配置 C 比配置 B 要好,因为额外的 1x1 卷积层为 C 增加了深度;配置 D 比配置 C 好,因为 D 将 C 中的 1x1 卷积层替换为了 3x3 卷积层,这增加了卷积层的感受野)。其中比较值得关注的是 Q = 384 与 Q = 0.5(Smin+Smax) 的对比,前者是使用 fixed S 训练得到的,后者是使用 jittering 的 S 训练得到的。两者在测试时的输入都是 fixed Q = 384,而结果却表明了,使用 jittering 训练能明显提升网络表现。
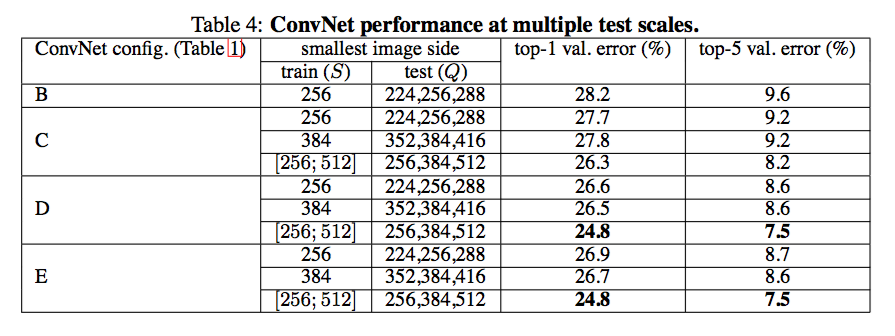
Multi-Scale Evaluation
在测试 fixed S 模型时,Q = {S-32, S, S+32},在测试 jittering S 时,Q = {Smin, 0.5(Smin+Smax), Smax}。根据结果,我们能发现 jittering 的 testing 输入也能提升网络的表现。对于为何 jittering 的输入也能提升 fixed S 模型的表现,我想不到一个合理的解释。
Multi-Crop Evaluation
作者在初稿时貌似没有使用 multi-crop,而是出于效率考虑,使用了 densely。而实验结果表明,multi-crop 与 densely 的均值能带来最好的表现。作者假设结果的提升是来自两种方法使用了不同的 padding 方式。
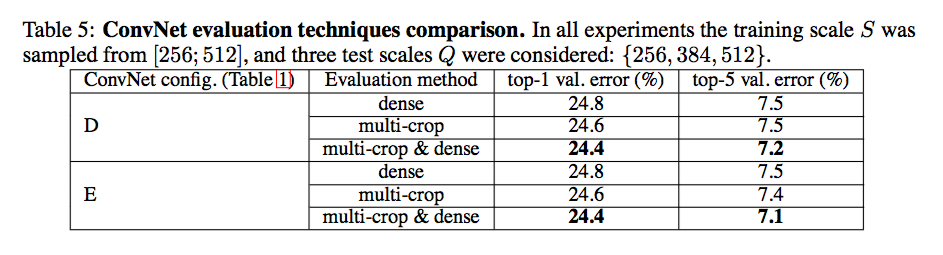
ConvNet Fusion
作者只是比较暴力地对不同网络的分类概率求了平均值,事实证明,这样也能提升网络的表现。

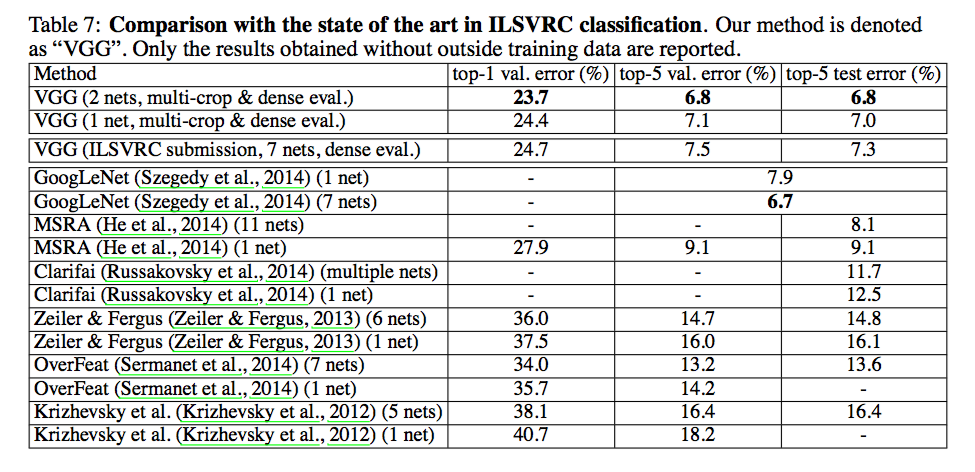
Comparison
这个数据只用参考一下即可。数据表明,有较大深度的 VGG 和 GoogLeNet 能获得更好的效果,其中 top-1 error 即预测值等于实际类标才视为正确,top-5 error 即概率最大的五个预测值包含正确类标则视为正确。
Localization
上文介绍的主要是使用 VGG 处理分类问题,在这里也补充说明一下用 VGG 处理定位问题的情况。这里有两种关于边界框预测的方案,一种是在所有类间共享的单类回归,另一种是针对特定类的每类回归。对于前一种输出的维度为 4x1,而在后一种则是 4x1000。除了最后的边界预测层外,前面使用的是配置 D 的卷积网络。
Training
由于时间限制,VGG 并没有使用 jittering S 的训练方式。且外,localization 网络的前 15 层使用了配置 D 的结果进行 fine-tuning,而最后一层则使用了随机初始化。
Testing
作者考虑了两种 testing 的方案。第一种只考虑不同的网络在验证集上的表现。网络的输入为图像的中心裁切,且只考虑 ground truth class 的输出。第二种则是使用 densly 的方法,先将获得的 1000 个预测边框中空间相近的边框进行合并,然后再通过这些边框在 classification 中的评分进行排序,获得最终输出。作者并没有使用 Sermanet 等人的 multiple pooling offsets technique 来提升预测边框的空间分辨率以进一步提升网络的表现。
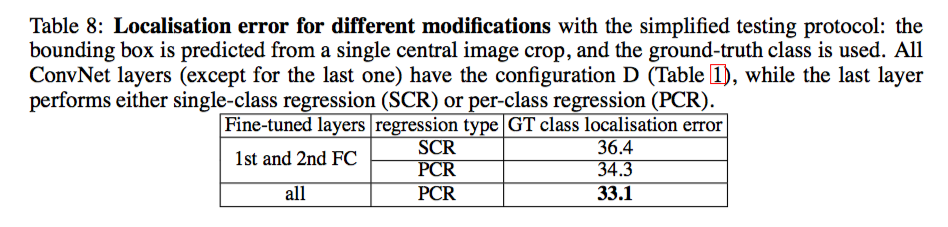
Settings Comparison
在这里,如果预测的边界框与真实边界框的重叠率大于 0.5,则被认为是正确的。我们可以留意到,PCR 的表现明显比 SCR 要好,且外,对所用层使用 fine-tuning 也能获得更好的效果。
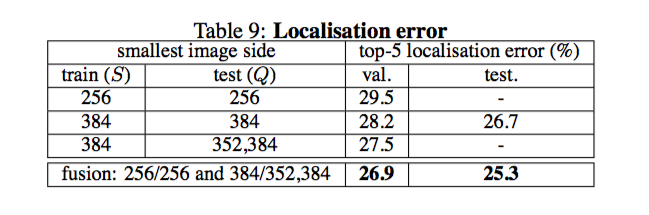
Fully-Fledged Evaluation
这里使用了之前得到的最好的 setting (即 PCR 加 fine-tuning),然后我们可以发现,jittering Q 与 fusion 同样能提升网络在 localization 问题的表现。我估计使用 jittering S 与综合 multi-scale 和 densely 能进一步提升效果。
Generalization of Very Deep Features
在本章,VGG 将作为其他更小数据集的特征提取器,而结果也表明了 VGG 在其他数据集上的泛化能力很好。作者把 VGG 的最后一个全连接层去除,用倒数第二个全连接层的 4096 维的激活作为图像特征,且在整个过程中不对 pre-trained 网络进行修改。作者在训练时用到的策略与 classification 问题中的基本一致,不同的是这里对不同输入尺寸的网络进行了集成学习 (这里用到的是 stacking,对于这个问题,我觉得 boosting 也是一种可行的方案)。若干的实验数据表明,VGG 在不同的数据集上都能获得很好的效果。
Conclusion
VGG 是基于较大的训练集而训练得到的,而且它的参数数目最多可达到 144M 个,用四个 NVIDIA Titan Black GPU 来并行计算两到三周才能得到一个网络。因此,在开发自己的项目时,对 VGG 进行 fine-tuning 是不太实际的。但是,这篇文献中使用到了大量的训练 CNN 的技巧,而这些技巧都是很值得学习的。即便没有要修改 VGG 的打算,加深对它的了解也能让我在日后更好地把它应用到自己的项目中。