学习报告(week 8)
Integrated unpaired appearance-preserving shape translation across domains
Introduction
这篇论文通过结合 Cycle-consistency、Shared-latent space、Context information,使用 GAN 来解决无监督的风格迁移问题 (un-supervised geometric image-to-image translation),这里的风格迁移并不仅限于一些与艺术有关的内容,也可以拓展至人脸方面的内容。接下来,我们先介绍一下文章中出现的主要概念:
image-to-image translation (I2I),即广义上的图像生成问题。
domains,在同一个 domain 中的图片会拥有一些共有的特征,比如照片与图画可以算作两个不同的 domains。
style transfer,同一个 domain 中的图片可能有不同的 style,我认为这里的 style transfer 可以理解成 Gatys 等人提出的风格迁移概念。
content,即与 style 相对的概念,在这篇文章中可以理解成物体的形状与图像的全局结构。
Methodology
首先,我们可以先了解一下模型的整体结构。
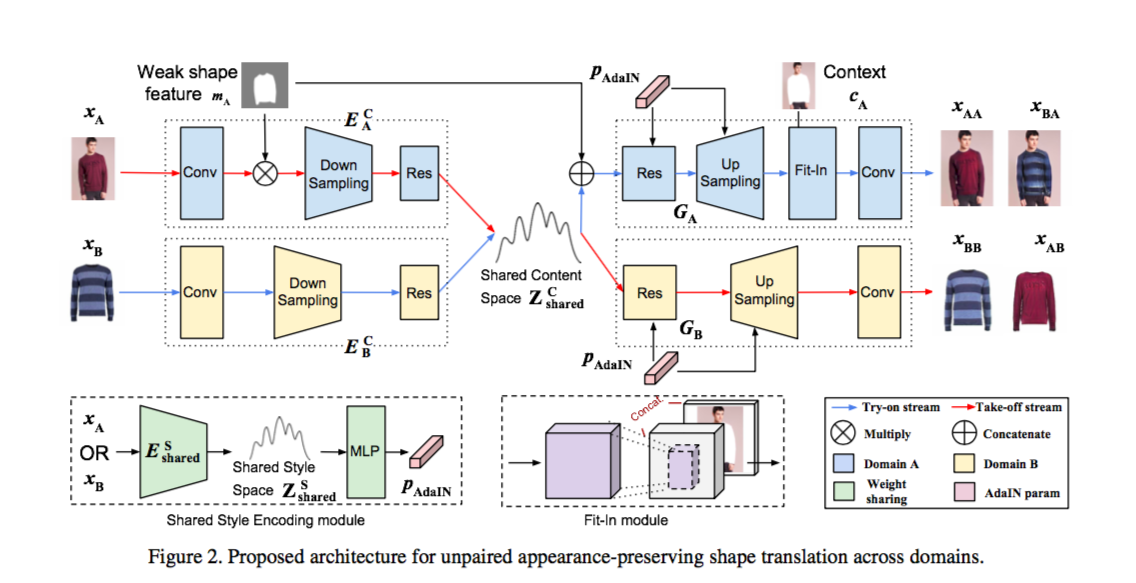
我们使用 try-on/take-off 系统作为例子,记人像图为 domain A,记服饰图为 domain B。那么,我们可以用 XA 表示人像图的输入,用 XB 表示服饰图的输入。而对于 domain A -> domain B 的转换,我们可以记为 XAB。我们用 EC 与 ES 分别表示 content encoder 和 style encoder。
Cycle-consistency
这部分参考了 J. Zhu et al. 在 Unpaired image-to-image translation using cycle-consistent adversarial networks 中提出的模型。CycleGAN 是无监督的,只需要使用 unpaired input 就可以训练出对应的模型。一般来说,如果我们想生成 XAB,那么我们需要训练一个模型 FA->B 满足 XAB = FA->B(XA)。而在无监督的情况下,模型很有可能会无视掉我们设定的条件 (比如在 A->B 的过程中,忽略了 A 的特征,单纯生成与 B 的图片)。而在 CycleGAN 中,我们将同时训练 FA->B 与 FB->A,我们要使 FA->B 与 FB->A 可逆 (即满足 XA = FB->A(FA->B(XA)) 与 XB = FA->B(FB->A(XB)))。
Shared-latent space
首先根据其他论文提出的方法,将输入分解成 content space 与 style space。我们假设下列两条约束:A 与 B 共享一个 content space;A 与 B 的 style space 相同。这些约束通过定义 latent content code reconstruction loss 与 latent style code reconstruction loss 来实现,这部分的内容将在后文详细介绍。
Context information
这部分的内容可以理解为 refinement,为了更好地把关注点放在服饰部分,作者先使用 human parser 来提取出 XA 的服饰部分。其实在 VITON、M2E-TON 等研究中也使用了相同的做法,但是在这里,作者使用的是 K. Gong et al. 等人在 2018 年发表的 Look into person: Joint body parsing & pose estimation network and a new benchmark 的成果。这个新的 parser 的作者其实与 VITON 等使用的 parser 的作者是同一个人,而这个新的 parser 估计是在之前的成果上进行了优化。而这部分的流程也与 VITON 的 Multi-task Encoder-decoder Generator 类似,因此在后文中就不再详细介绍了。
Try-on stream
对于 FB->A,我们先把 XB 输入到网络中,通过 content encoder 获得 ZBC。同时,我们也使用 style encoder 来获得 ZBS。需要注意的是,因为我们先前就假设 A 与 B 的 style space 相同,所以 A 与 B 共用一个 shared style encoder。整个模型是残差网络,作者使用了自适应实例归一化 (AdaIN) 来结合 content 信息与 style 信息。AdaIN 即 content image 的 feature 分布拉伸到 style image 的 feature 分布,这样就在特征空间完成了风格变换。
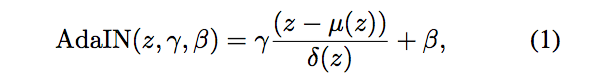
我们使用上述公式完成 AdaIN,其中 z 为上一层的输出,μ 和 δ 分别是所有通道的均值和标准差。γ 和 β 由 style encoder 的输出经过多层感知器 (MLP) 得到。假设 XB 通过 style encoder 的输出为 y,我们也可以使用 μ(y) 与 δ(y) 来分别替代 β 和 γ。
我们用 content encoder 的输出与 clothes map 的集联作为 decoder 的输入,这个操作在 VITON 等研究中也有出现。之后,我们可以获得和 XA 的 clothes map 形状相同的 XB 的图片。我们还需要另外添加一个 fit-in module,把服饰部分和 XA 人体部分整合在一起。因为接下来还需要通过卷积层,所以在 fit-in module 中,我们只需要把上一层的输出与 XA 人体部分集联在一起即可。
Take-off stream
整个流程与 Try-on stream 类似,不同的是,我们用 XA 作为网络的输入。由于没有使用 Pose heatmap,我们要先计算出 XA 与 clothes map 的数乘。且外,在 Take-off stream 中,我们无需添加 fit-in module。
Learning
在这部分,我们只需要重点讨论下使用到的 loss function 即可,至于 implementation details 我们只需关注以下两点:
- 对于 perceptual feature extractors Φ,作者选用了 LPIPS。
- 在下文的 Evaluation 中,SD 代表 style code 向量的维度。
接下来,我们将重点讨论下模型使用到的 loss function:
- Bidirectional Reconstruction Loss,其中,LSR 表示像素层面上与 ground truth 的误差,LLR 表示 latent space 层面上与 ground truth 的误差。对于 LSR,我们只用计算 XA 与 XAA 的差的一范数即可;对于 LLR,我们要计算 XA 与 XAB 经过 encoder 后的输出的差的一范数。具体公式如下:
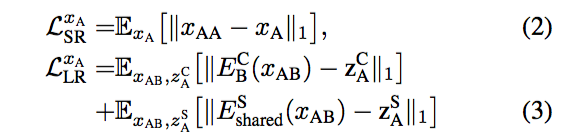
- Cycle-Consistency Loss,即 reconstruction loss,是 CycleGAN 最重要的 loss。可以理解成优化 XA = FB->A(FA->B(XA))。具体公式如下:
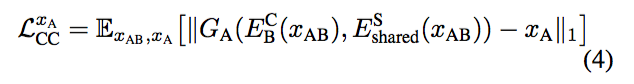
-
Adversarial Loss,以判断生成出的图片的真实性。
-
Perceptual Loss。首先令 XA’ 代表 Region of Interest,在这里即服饰部分。之后分别使用 LPIPS、GRAM 矩阵来表示图片的感知。对于 GRAM 矩阵,作者使用了 VGG16 来提取出特征。具体公式如下:
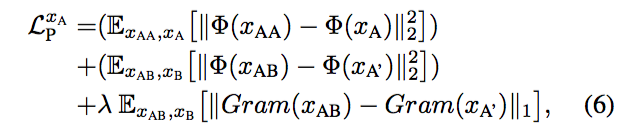
- Symmetry Loss,这个对称误差是基于先验知识的,我们需要先假设得出来的结果是对称的,然后计算对应位置的像素差的一范数。具体公式如下:
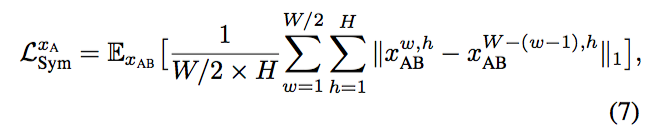
Evaluation
作者使用了控制变量的思想,每次改变模型的一个模块来验证每个模块的作用。根据对比图可以发现,无论是删减掉 Perceptual Loss、Shared Style Encoder、Discriminator Attention、Mask Guidance 中的哪一个都会是模型表现下降。且外,作者也尝试了使用有监督训练与取定不同的 sytle code 的维度。最后我们可以得出结论:加大 SD 并不能使模型获得更好的表现;有监督学习能让模型保留下更多纹理方面的细节。

Conclusion
总的来说,这篇文章与我以往阅读过的虚拟试衣方面的文章相比,最大的特点就是使用了 CycleGAN 来实现无监督学习。这无疑能解决获取数据集难的问题,但相对的,我们也需要额外设计一个 Take-off stream。因为我不是很了解 Take-off stream 方面的内容,所以没办法分析 Take-off stream 方面的设计。我认为,这篇文献结合了 CycleGAN 与 latent space 的方法对我们以后设计模型很有启发价值。
实际上,这篇文章的研究成果还涉及 Clothing Retrieval 与 Face Shape Translation 方便的内容,但由于与我们要做的研究的相关性并不大,这里就不做赘述了。最后,我想提及下自己对这篇文章的一些见解:
- 作者在实现 Try-on stream 时并没有添加 refinement module,这导致模型不能很好滴地还原一些复杂的纹理。在我看来,作者可以在 fit-in module 处额外集联上服饰图片的 warping。而这个 warping 可以使用简单的 TPS 来完成,也可以通过训练一个网络来完成。
- 作者定义了一个 Symmetry Loss,而假设服饰图片是对称的话,就会导致模型在处理一些复杂的纹理时的输出变得比较模糊。这样的假设用在人脸上是比较合理的,但出于尽可能保留纹理的考虑,我认为去除掉 Symmetry Loss 会比较好。