学习报告(week 7)
M2E-Try On Net- Fashion from Model to Everyone
Introduction
这篇论文的研究方向也是虚拟试衣系统,但与先前的一些研究成果不一样:M2E-Try On Net 不需要用户提供服饰的正面照,只需要用户提供穿着特定服饰的模特的照片,即可生成出对应的试衣图像。M2E-TON 由三个网络构成:the pose alignment network (PAN)、the texture refinement network (TRN)、the fitting network (FTN)。
首先,M2E-TON 的总体流程如下:
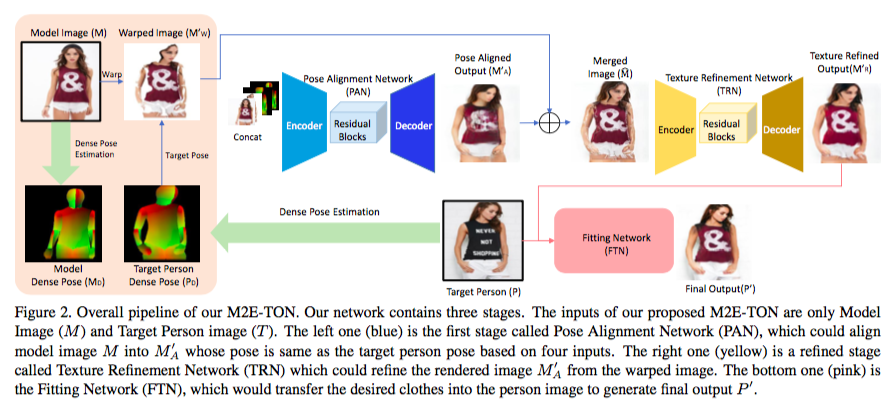
其中,网络的输入包括 Model Image M 与 Target Person P 的 Dense Pose。DensePose 是由 Facebook 提出的一种密集人体姿态估计,它建立了 RGB 图像和人体 surface-based 表示之间的密集对应关系。在之前学习过的 VITON 中,VITON 的作者使用了 18 个 keypoints 来表示人体的姿势,而 M2E-TON 的作者认为使用 DensePose 来可以获得更好的效果。
在获得了 M 与 P 的 Dense Pose(分别记为 MD 与 PD)后,作者基于 MD 与 PD 把 M 拉伸至 P 的姿势,我们将获得的 Warped Image 记为 MW。
接下来,作者将 M、MD、PD、MW 的 concatenation 输入到 PAN 中,获得 Pose Aligned Output MA。但是到目前为止只能较好地将 M 拉伸到 P 的姿势,且外,这种简单的 GAN 做法会导致 M 身上的服饰的纹理变得模糊。
为了解决这个问题,作者将 MA 与之前获得的 MW 融合在一起,然后输入到 TRN 中。TRN 能将 MA 与 MW 融合产生的边缘去掉。之后,我们就能获得 M 与 P 姿势相同时的图片 MR。
考虑 MR 与 P,我们的任务就只剩对两幅图片的服饰部分进行风格迁移了。作者将 MR 与 P 输入到 FTN,并获得最终输出 P’。
Pose Alignment Network (PAN)
在上文中,我们已经对 PAN 做了粗略的介绍了,而较详细的流程如下:
- 首先使用 Densepose: Dense human pose estimation in the wild 的成果,获得 MD 与 PD,它们分别由 24 个部分组成。
- 对于 MD 与 PD 的每组对应部分,使用纹理坐标进行重心坐标插值 warping,获得 MW。
- 将 M、MD、PD、MW 集联成 256 x 256 x 12,将其作为 PAN 的输入。即原图像皆为 256 x 256 x 3 的 RGB 图像。
PAN 的网络结构比较简单,就是普通的 Encoder-Decoder 结构。但是作者并没有使用深度网络来提升表现,而是使用了残差网络。对比起一般的深度网络,残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这样能使网络更容易学习。
Texture Refinement Network (TRN)
TRN 用于增强 MA 的细节,把融合 MA 与 MW 生成的边缘去掉,使图像变得平滑。TRN 与 PAN 的结构相似,这里就不做赘述了。
Fitting Network (FTN)
FTN 的流程如下:
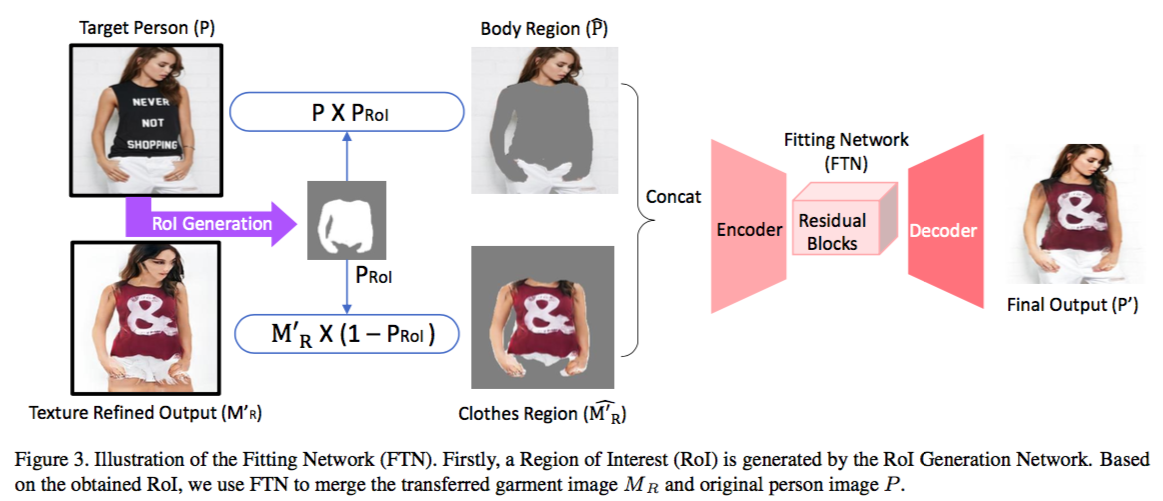
首先,作者使用与 VITON 一样的方法,提取出 clothes mask。这种方法为 Self-supervised structure-sensitive learning and a new benchmark for human parsing。之后,作者使用 DensePose 提取出 upper body region mask,再将 clothes mask 与 upper body region mask 结合成一个 union mask。 为了获得更平滑的 mask,作者吧 union mask 作为 ground truth 来训练一个网络用以生成 Region of Interest mask(记为 PRoI),其中,网络的代价函数为输出与 ground truth 的 L1 范数。
在获得 PRoI 后,作者将 P 的身体部分与 MR 的服饰部分结合起来,作为 FTN 的输入。而 FTN 的结构也与 PAN、TRN 相似,因此这里也不再赘述了。
Unpair-Pair Joint Training
这部分内容是我认为这篇论文中比较有意思的部分,作者使用了一种比较新颖的训练方法。
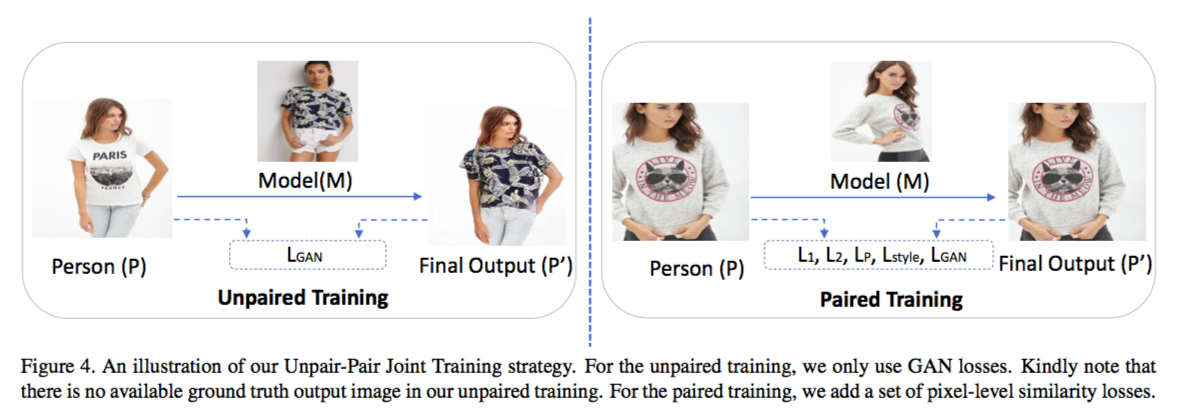
M2E-TON 本身是由 GAN 构成的,但是普通的 GAN 无法保持输入图像的姿势等特征。此时通常需要加入 Structure Loss、Perceptual Loss、Style Loss 等惩罚机制,而在缺少 ground truth 的情况下,以上的惩罚机制是无法实现的。作者在无法获得 ground truth 的情况下,提出了一种自监督的训练方法(称为 Paired Training),即将 P 同时作为输入与 ground truth,将同一个人穿着与 P 同样服饰的不同姿势的照片作为 M 来训练网络。作者也使用了普通的 Unpaired Training,但在 Unpaired Training 中,因为无法获得 ground truth,所以只考虑 GAN Loss。
Loss Functions
作者一共引入了 4 种 loss:
- Adversarial Loss,即普通的 GAN Loss,用以区分真实图像与生成图像。
- Reconstruction Loss,使用 P’ 与 ground truth 的 L1 范数与 L2 范数来保持生成图像的大体结构与原始图像一致。
- Perceptual Loss,使用 VGG16 网络来提取 P’ 与 ground truth 的特征,并以他们对应特征的 L2 范数作为损失。
- Style Loss,参考了 Gatys et al. 提出的方法,使用 Gram matrix 来衡量图像的风格。其中,Gram matrix 通过从 VGG16 提取的特征获得。作者最后将 P’ 与 ground truth 的 Gram matrix 的 L2 范数作为损失。
Conclusion
总的来说,M2E-TON 与 VITON、CP-VTON 等的成果大同小异,具体的差异如下:
- M2E-TON 使用模特照片作为服饰输入,而不像 VITON、CP-VTON 一样使用单纯的服饰图片。
- M2E-TON 使用了 DensePose 来获得 human representation,而 VITON、CP-VTON 则是使用了 Gong et al. 的研究成果。
- M2E-TON 在预处理的 warping 操作中使用的是基于 Dense Pose 的 barycentric coordinate interpolation,而 VITON 使用的是 TPS,CP-VTON 使用的是 GMM。
- M2E-TON 加入了 residual blocks 来优化网络。
在训练方法上,M2E-TON 采用了 Unpaired Training 与 Paired Training 结合的方式来解决缺少 ground truth 的问题。不过实际上,我认为 Paired Training 对模型表现的贡献会远比 Unpaired Training 大,在此类问题中,使用无监督的方法很难获得较好的结果。且外,我也认为 M2E-TON 的研究价值远比实践价值要大,毕竟在现实生活中,我们在网购时很少会遇到无法获得服饰图片的情况。虽说如此,我还是认为这篇论文在实现细节上给我提供了很多有用的参考,包括 DensePose 与 residual blocks 的使用等。
SMPLify Demo Test 3
在阅读了 Photo Wake-Up 3D Character Animation from a Single Photo 后,我发现该论文作者也使用了 SMPLify 来拟合 2D 人像的 SMPL 模型。唯一不同的地方在于,作者加入了一个变形的步骤,来将半裸的 SMPL 模型变形成穿着衣服的形状,以方便后面的贴图操作。但是,这个操作对我们的项目来说好像并没有什么意义,因此,我进一步思考了之前运行 SMPLify 效果不佳的原因。
首先,我使用了 DeepCut 提供的 demo 图像,获得了一组预测节点。然后,我将这组节点输入到 SMPLify 中,获得了如下的结果:

对于这组输入,我们获得了不错的结果,因此,我们可以把问题锁定在 DeepCut 上。而 DeepCut 是通过 CNN 来实现的,我们很容易就能联想到 DeepCut 的表现与输入的 scale 有关。接下来,我在对 LSP 数据集的人像进行 rescale 后,再输入到 DeepCut 中,之后再将 DeepCut 的输出输入到 SMPLify。

此时,我们终于能在 LSP 数据集上获得不错的结果了。但是,我们尝试其他的输入时,DeepCut 却不能提供较准确的预测结果。

而在 Photo Wake-Up 3D Character Animation from a Single Photo,作者使用的虽然是 SMPLify,但却没有使用 DeepCut 来获得 2D 预测节点,而是使用了 Convolutional Pose Machines 作为替代。在进一步阅读 SMPLify 官方网站后,我发现 CPM 也是官网认可的 DeepCut 的一种替代方案。因此,接下来,我决定使用 CPM 来尝试能否获得更好的结果。