Learning to Estimate 3D Human Pose and Shape from a Single Color Image
Introduction
这篇论文主要介绍了一种全新的全自动的根据单幅 2D 人像生成对应 3D SMPL 模型的方法。与先前 Bogo et al. 与 Lassner et al. 提出的方法不同,论文中提到的方法没有使用迭代优化的方式来拟合模型,而是通过训练一个 CNN 来获得 SMPL 模型的 β 与 θ 参数。与迭代优化的方式相比,训练 CNN 的方法可以显著减少 online training 的开销,同时使模型的抗干扰能力更强(即能更好应对无法准确获得 2D 关节点的情况)。
网络的整体框架如下。
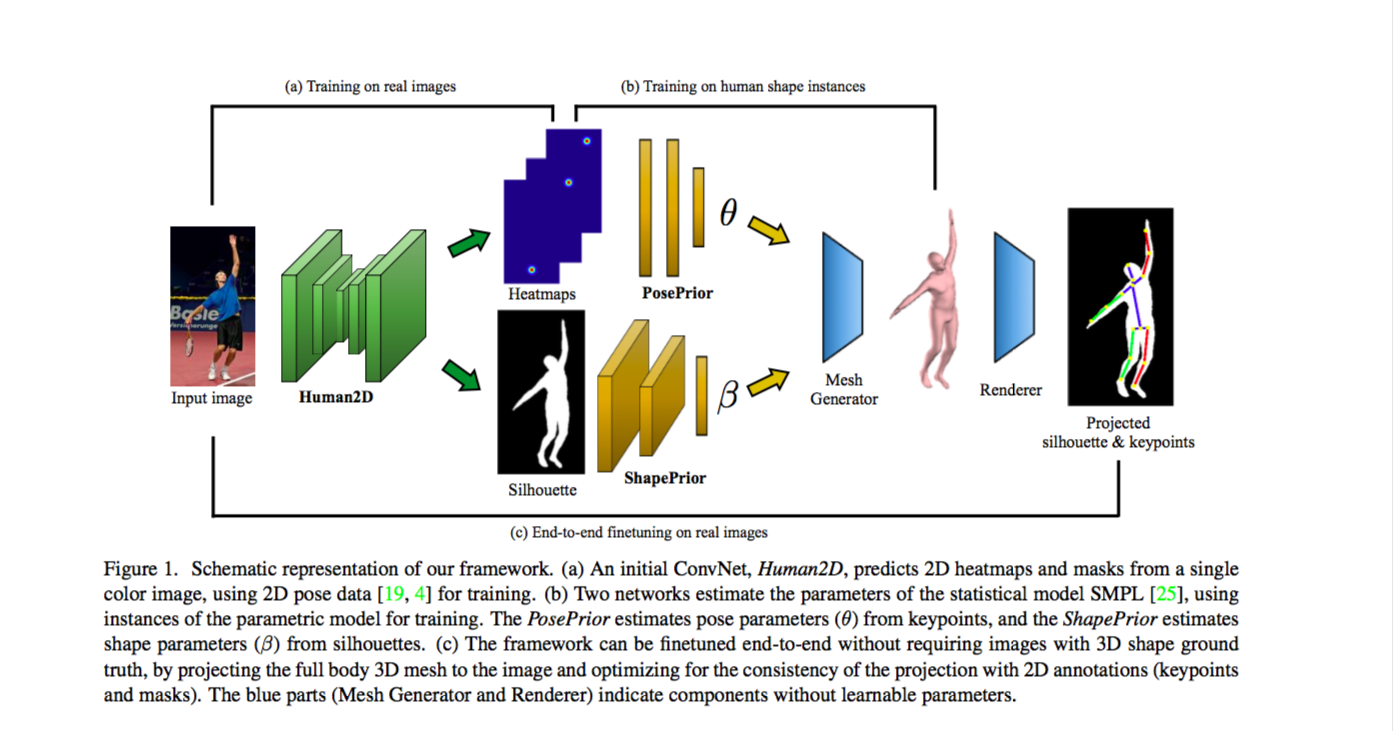
首先,我们将一幅 2D 人像输入到网络中,通过 Human2D 网络获得人像的关节点热点图(heatmap)与人体轮廓(silhouette)。接下来,我们把关节点热点图输入到 PosePrior 网络来获得一组 θ 参数,把人体轮廓输入到 ShapePrior 网络来获得一组 β 参数。在获得 β 与 θ 参数后,我们可以使用 Mesh Generator 生成一个 SMPL 模型。考虑到通过 CNN 获得的参数未必准确,在最后我们还需使用 Renderer 把模型投影成 2D,然后通过比较投影与原始输入的关节位置和轮廓来进行微调(finetuning)。
与我之前学习过的 Bogo et al. 提出的方法不一样,Pavlakos et al.(本文作者)提出的方法额外考虑了人体轮廓的影响。Pavlakos et al. 认为引入人体轮廓能够更好地保留人体的 shape 信息。实际上,引入人体轮廓的做法最早是由 Lassner et al. 提出的,但由于我没有看过 Lassner et al. 的论文,这里就不对此做讨论了。
Human2D
在过去,预测人像关节点的网络与预测人像轮廓的网络通常是独立的。作者训练了 Human2D 网络,这个网络能同时输出人像的关节点与人像轮廓。考虑到目前在这一领域已经有不少不错的研究成果,作者只是主要参考了现有的研究成果,并做出了一些微小的修改。首先,作者使用了现有的带人工标注的数据集进行训练,然后根据经验尝试设计了一个包含两个 Hourglass 模块的网络,其中,Stacked Hourglass 模块的结构如下。
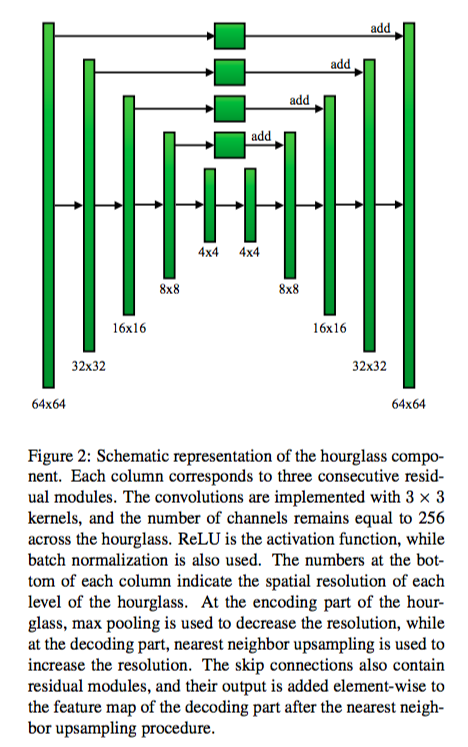
每个 Hourglass 模块都是一个四阶的 Hourglass 子网络。我们只考虑一阶的 Hourglass 子网络的话,子网络有上下两个半路,包含若干个 Residual 模块。一般来说,如果我们想提取更深层的特征,我们需要先进行降采样再进行升采样。但 Hourglass 网络的发明者认为,在不同的尺度上,方便提取出来的特征是不一样,某些特征可能在原尺度上更容易被提取出来。因此,Hourglass 网络与传统方法不一样,在改变尺度特取特征的同时,也在原尺度上进行提取,最后再综合两路的结果得出最终结果。我没有仔细研究过 Stacked Hourglass 网络的优劣,但这种网络貌似被广泛应用于姿态检测研究上。
而整个 Human2D 网络除了 Hourglass 模块外,还包含若干个卷积层,详细结构如下。
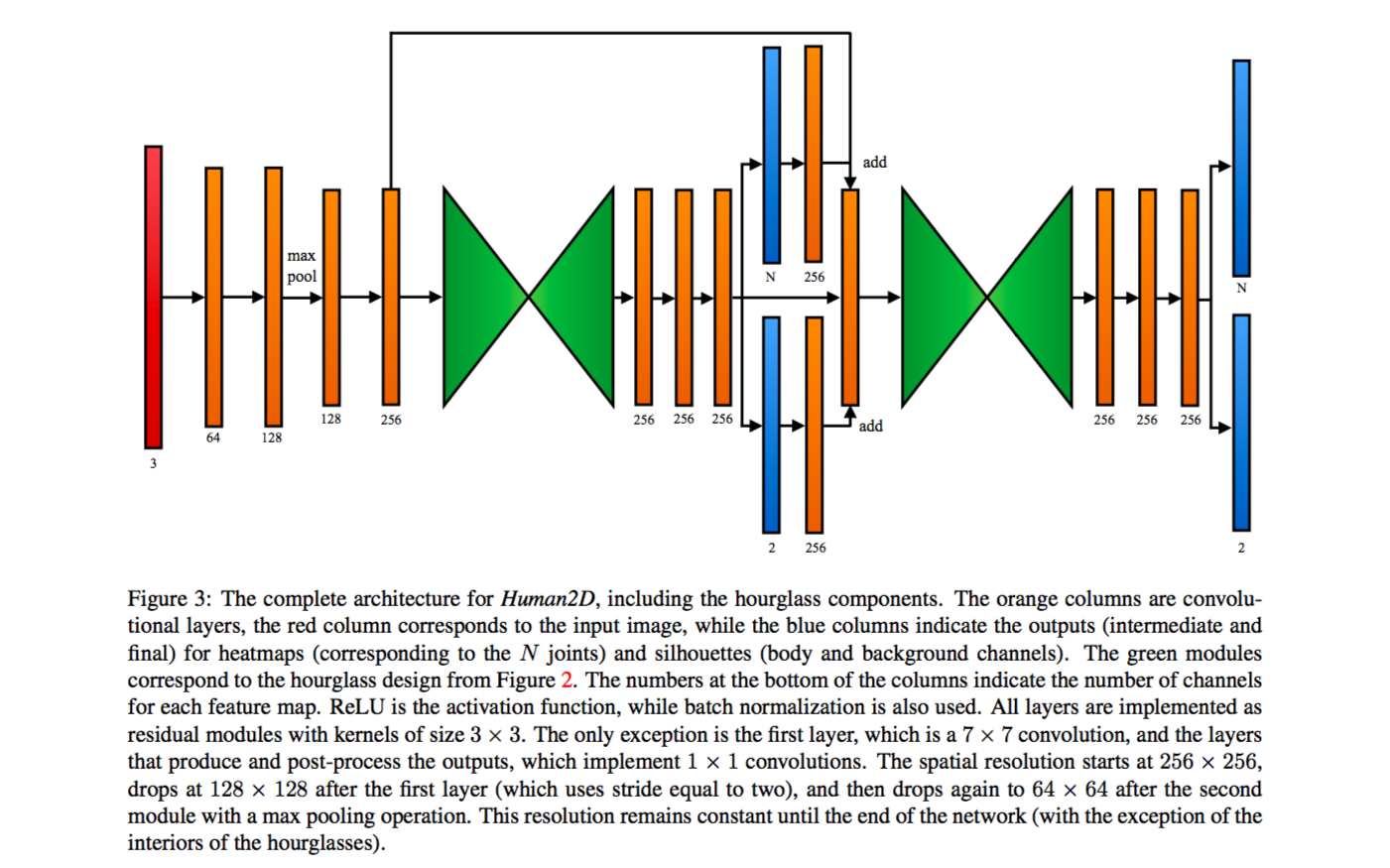
预测关节点的输出格式为热点图,预测轮廓的输出格式为双通道轮廓图(前景与背景)。作者用 ground truth 与 prediction 的 MSE loss 作为关节点预测的目标函数,记作 Lhm;用 ground truth 与 prediction 的逐像素 binary cross entropy loss 作为轮廓预测的目标函数,记作 Lsil。总目标函数 L = λLhm + Lsil,其中 λ = 100。Human2D 属于 multi-task learning,作者认为关节点的学习与轮廓的学习可以互相促进,但前提是选取合适的权重。因为现今无论 convolution layer 还是 pooling layer 的运用都挺广泛的,这部分的内容没必要做太多分析。但我认为,如果我们想要实现自己的模型生成算法的话,关节点与轮廓的获取应该是必要的,所以 Human2D 网络对我们有较大的参考价值。
PosePrior & ShapePrior
在这部分,作者将关节点位置与对应的自信度(热点图的最大值)输入到 PosePrior 网络中,然后计算出 SMPL 模型用于姿势变形的 θ 参数。由于在现实中,我们很难获得一张 2D 人像对应的 SMPL 模型 ground truth,作者将 PosePrior 与 Human2D 的训练区分了开来。在训练 PosePrior 的过程中,作者先用 MoCap 获得一系列拥有不同 pose 的 SMPL 模型,然后将获得的模型映射到 2D 上。基于这些 2D 的映射图片,作者计算出对应的关节点和轮廓,再将这些计算出来的数据作为 PosePrior 的输入。换句话说,即先获得 ground truth,然后通过 ground truth 来计算出输入。
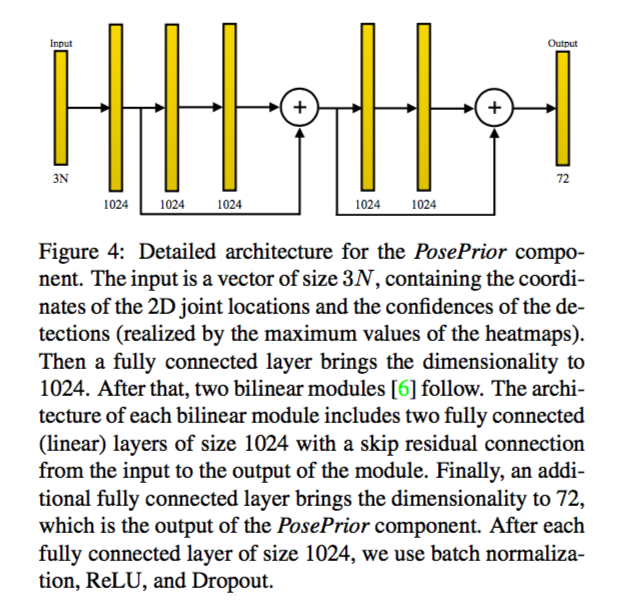
至于 ShapePrior,我们需要将轮廓输入到 ShapePrior 网络中,然后计算出用于体型变形的 β 参数。这里的训练方法与 PosePrior 的大致相同,唯一不同在于 ground truth 是通过 3D body scan 获得的。
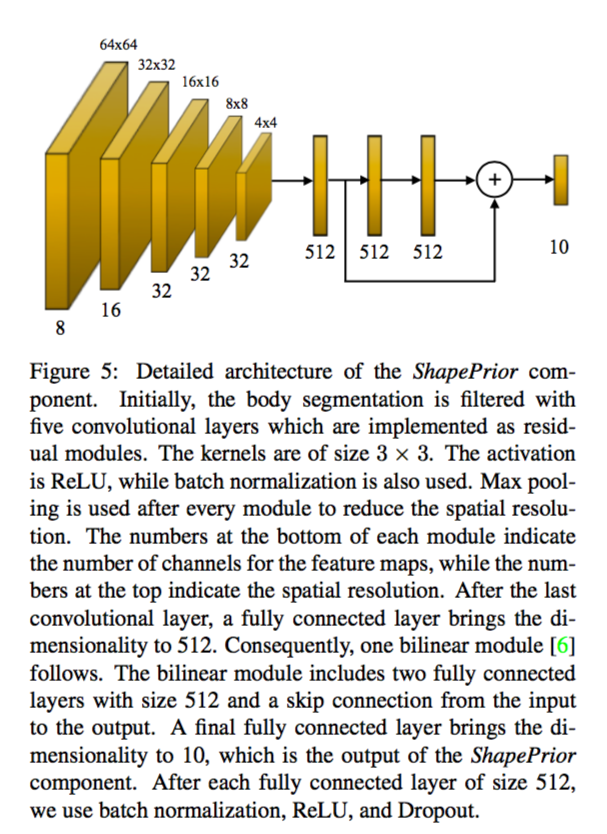
在实践过程中,作者发现,在最开始时使用参数间的 L2 loss 作为目标函数,到最后再改用由参数生成的模型的顶点间误差或关节点间误差作为目标函数会获得较好的效果。理论上,在已知 β 参数的情况下,我们能够训练出更好的 PosePrior。但作者提到,这个操作不仅会让模型变复杂,而且还会影响模型的稳定性。对于作者的这点看法,我认为采取不一样的训练方法的话,很有可能能在已知 β 参数的情况下,训练出更好的 PosePrior。根据 SMPL 模型的原理,模型实现通过 β 参数进行基于模版模型的形变,再考虑 θ 参数的影响,即:对于不同的 β 参数,同一组 θ 参数对姿势的影响会有所不同。因此,我认为单纯考虑 θ 参数的 PosePrior 并不能获得理论上的最好效果。
因为 PosePrior 与 ShapePrior 的结构都比较简单,这里就只给出它们的结构,不进行具体分析了。
Renderer
这里用到的 Renderer 是 OpenDR,与 SMPL 和 SMPLify 使用的一样。使用 OpenDR 进行投影的话,我们需要获得 focal length 和 global translation。作者把 focal length 固定为 5000(SMPLify 中固定的是 1000),然后令投影的长与 ground truth 轮廓的长一致,估算出一个 global translation(摄像机位置)。与 SMPLify 不一样,在这篇论文中,作者貌似没有考虑人体的朝向。作者使用下列公式作为目标函数,其中:W 代表关节点,S 代表轮廓。
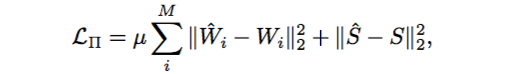
公式中的 μ = 10。作者分开了两部分进行 finetune(先 finetune Human2D 再 finetune 两个 Prior 网络),其中:关节点的误差使用了 MSE loss,轮廓的误差使用了 pixel-wise binary cross entropy。
Boosting SMPLify
SMPLify 在训练过程中逐步减小 objective function 中 λθ 与 λβ 的值来防止陷入局部最优。因此,我们可以将 SMPLify 的优化过程划分成四个阶段,前三个阶段主要针对计算出一个粗略的模型,最后一个阶段作用类似 finetuning。Pavlakos et al. 提出:我们可以使用他们的研究成果作为 SMPLify 的初始化,然后直接进行 SMPLify 的阶段四,从而提升 SMPLify 的表现。不过,我们需要引入额外的误差项来防止 Boosting SMPLify 的结果偏离我们的初始化参数。
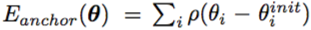
公式中的 ρ 表示 Geman-McClure penalty function。
Conclusion
我认为 Evaluation 与 Comparison 就没必要详细介绍了,而考虑到现有的方法都是 online 的,这篇论文提出的方法的 Running Time 显然会比较短。作者已经考虑到了结合 CNN 与 regression optimization(即 Boosting SMPLify)来进一步进行优化了,所以如果我们想要改进的话,发挥空间比较大的地方就是 PosePrior 了。传统方法主要是缺少了对 shape 的限制,而 Boosting SMPLify 中显然更强调 pose 的重要性,我觉得从原理上来说,我们应该尽量强调 shape 的重要性(尽管作者在 Boosting SMPLify 中通过实践验证了 pose 的影响更大)。且外,我认为在训练 PosePrior 时,考虑 β 参数并采取合适的方法能获得更好的结果。但到目前为止,我能想到的方法只有改用 regression 求 θ 参数,或更改 PosePrior 的网络结构。